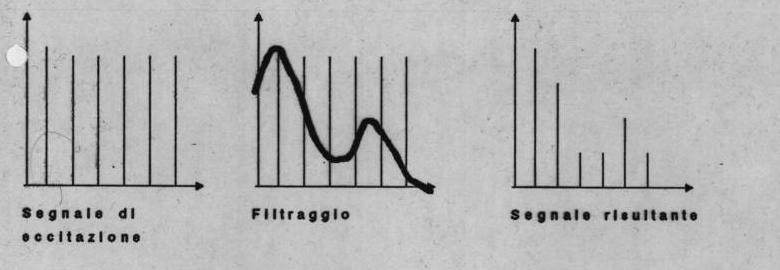
dove Generator è l'onda o rumore di partenza e Filter è uno o più filtri. L'effetto che si produce è il seguente
| Facilità di comprensione e
implementazione |
Il che si traduce in
semplicità di controllo e facilità d'uso. |
| Segnale variabile nel tempo |
Grazie ai filtri. Occorre però ricordare che
nella sottrattiva non si creano componenti, quindi queste
ultime devono essere già presenti nel segnale di partenza. |
| Velocità di calcolo | Buona velocità di calcolo se
non si utilizzano reti di filtri troppo complesse |
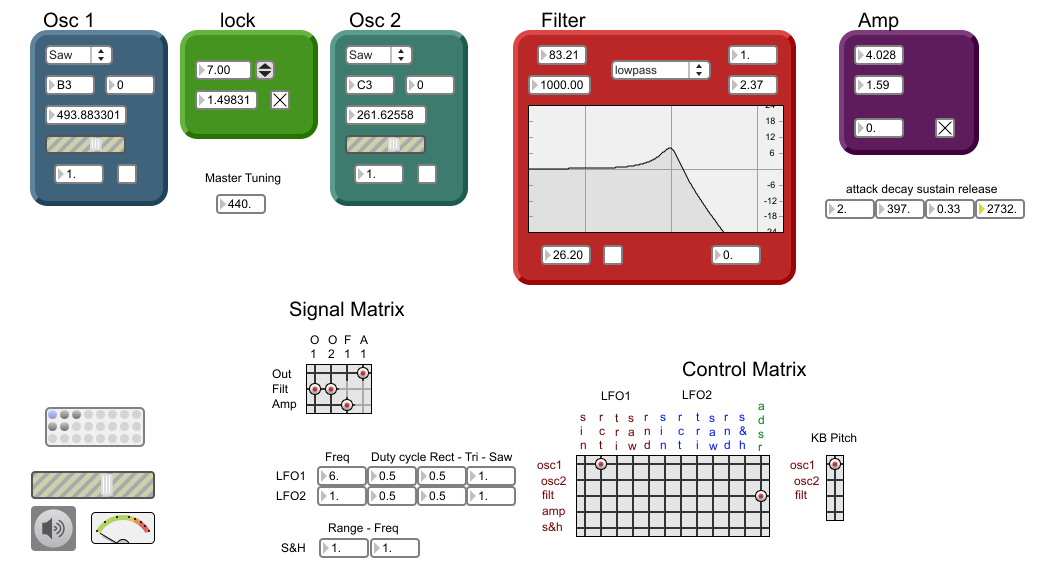
| Semplice generazione di suoni con formanti
fissi |
Molti suoni reali sono caratterizzati da
formanti fissi (praticamente tutti gli strumenti con cassa
armonica fra cui, vi ricordo, la voce umana). Con altre tecniche di sintesi è possibile crearli, ma non è così semplice. Con la sottrattiva, invece, basta aggiungere alcuni filtri di banda (vedi esempio più sotto). |
| Tipologia spettrale limitata |
La tipologia spettrale è strettamente legata
al segnale di partenza. Non si possono creare nuove
componenti e anche la selezione su quelle presenti è
grossolana, a meno di non ricorrere a filtri basati su FFT,
che però richiedono risorse di calcolo maggiori. |
| Correlazione fra le componenti |
La correlazione fra le
componenti è quella del segnale di partenza che, essendo, in
genere, un table lookup, soffre delle stesse limitazioni per
quanto riguarda tremoli, vibrati e deviazioni fra le
componenti che risultano impossibili da applicare
(ovviamente si può partire da un suono generato in additiva,
ma allora si perdono i vantaggi della sottrattiva) |
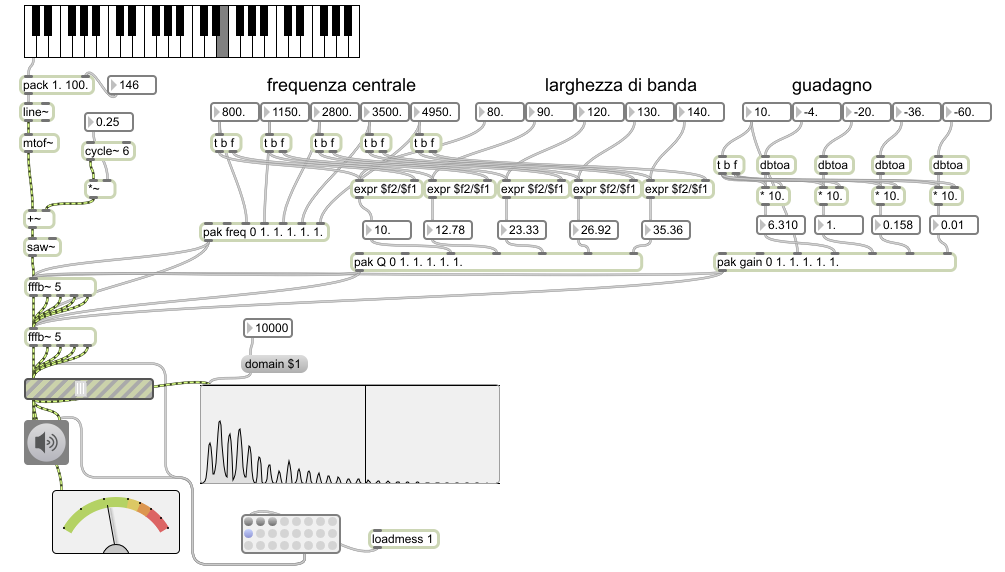
Questa patch mostra come sia facile creare formanti in
sottrattiva (e incidentalmente come sia possibile aumentare
l'ordine di un filtro mettendone due in serie).
Il modulo fffb~ di MSP crea un banco di filtri passa-banda. Qui
ne vengono definiti 5 a cui vengono passate, con appositi
messaggi, le frequenze centrali, le larghezze di banda e le
ampiezze per creare dei suoni con 5 formanti fissi.
Alcuni preset sono già memorizzati. Facendo varie note e
guardando lo spettro si vede (oltre a sentire) come quest'ultimo
cambi perché i formanti sono fissi e quindi le parziali che
vengono attenuate o amplificate cambino in base alla nota. Ciò
nonostante la qualità sonora è sempre la stessa. Per es. il
primo preset assomiglia a una A e resta sempre tale anche se lo
spettro effettivamente cambia.