Consigli utili per registrazioni casalinghe:
Archivi categoria: Audio
Cronologia della Tecnologia Audio e della Musica Elettroacustica
Ho finalmente aggiornato la pagina dedicata alla Cronologia della Tecnologia Audio e della Musica Elettroacustica.
Mancano ancora un po’ di cose, comunque è quasi completa e consultabile, con molte immagini, link di approfondimento e link per ascoltare via You Tube le composizioni citate.

Reverberation as music
Un cantante all’interno del Battistero di S. Giovanni a Pisa, in Piazza dei Miracoli (quella della famose torre) utilizza le qualità acustiche del luogo per trasformare una melodia monofonica in armonia.
Il Battistero ha un riverbero di circa 15 secondi che fa risuonare ogni nota per un tempo sufficiente ad sovrapporne altre. In tal modo il riverbero assume un significato strutturale nella composizione. Ovviamente questo è solo una dimostrazione dell’acustica del Battistero, ma, come potrete sentire seguendo i link ai post collegati sotto a “potrebbero interessarti anche…), a volte vengono scritti dei brani per sfruttare le qualità di certe architetture.
Un brano scritto proprio per il Battistero di Pisa è Voci della Terra e del Cielo di Ian Costabile che si può ascoltare su You Tube. Esiste anche un brano elettroacustico progettato per il Battistero: SiderisVox di Leonardo Tarabella, eseguito nel 2006. Ne trovate testimonianza qui. Purtroppo non sono riuscito a trovare un estratto audio.
Alcune precisazioni sulle note al video: il turista pensa che quel cantante sia entrato per caso, ma non sa che queste dimostrazioni sono frequenti. In certi periodi dell’anno se ne fa una ogni mezz’ora (nelle pagina di questo video, su You Tube ne trovate parecchie). Inoltre chiama l’effetto “eco”, quando ovviamente si tratta di riverbero.
IRCAM Prepared Piano
UPDATE 2023
L’IRCAM Prepared Piano 2 è una produzione IRCAM in collaborazione con UVI. Trattasi di un VST che simula sia il pianoforte che il piano preparato, basato su più di 12000 campioni di alta qualità per una libreria di circa 18 Gb. Oltre a vari tipi di pianoforte, vengono emulate 45 tipologie di preparazione, tecniche estese ed effetti, tutti copiosamente descritti al link iniziale. Prezzo $ 209.
Typedrummer
Un’altra drum machine online basata sui caratteri alfanumerici.
Questa è più carina del solito. Viene bene perfino “devi morire“.
Le maiuscole e le minuscole sono uguali; lo spazio introduce una pausa. Non si può cambiare il metronomo né scaricare un file (dovete registrare il loop).
Badate ad utilizzare un numero di caratteri multiplo di 4 se volete il vostro fanatico 4/4.
Soundscapes & Sound Identities
Inizierà venerdì 22 al Castello di Beseno (Rovereto) il VII Simposio Internazionale FKL sul Paesaggio Sonoro.


Suoni misteriosi dalla stratosfera
Una serie di suoni non ancora spiegati sono stati registrati da un veicolo NASA HASP. High Altitude Student Platform: è un veicolo di supporto che viene attaccato a un pallone sonda che lo solleva fino a 36 km per 20 ore. Il veicolo è destinato a ospitare esperimenti progettati dagli studenti.
È stato un microfono a bassa frequenza a registrare questi strani e per niente affascinanti (checché ne dicano i giornali) suoni nella banda fra 0.01 e 25 Hz. Frequenze bassine 🙂 Per renderli udibili si è reso necessario accelerarli di 1000 volte. Un bel salto di circa 10 ottave per cui, ascoltandoli, non cercate di immaginare che cosa potrebbero essere perché l’originale è molto, ma molto diverso.
In pratica sono semplici vibrazioni che potrebbero anche essere state provocate dal cavo che collega l’HASP al pallone aerostatico, per cui niente panico; non è il caso di parlare di alieni. L’unica cosa che ha una qualche connessione con gli alieni è il fatto che lo studente dell’Università del North Carolina che ha progettato l’esperimento si chiama Bowman (ricordare 2001 Odissea nello Spazio).
Le spiegazioni finora ipotizzate sono legate ai venti e alle variazioni della pressione atmosferica (nella stratosfera c’è aria: è solo il secondo strato dell’atmosfera).
Nel frattempo la notizia è stata raccolta da tutti i principali giornali che l’hanno condita con la potente parola magica “X-Files” e Repubblica è riuscita, come sempre, a infilarci lo strafalcione traducendo “infrasound microphone” con “microfono a infrarossi”; un peccato veniale rispetto a quelli che fa di solito.
Eccovi la registrazione.
Fonte/Source: Live Science
(((.foundsoundscape.)))
(((.foundsoundscape.))) is “a live radio collage of foundsound places to underscore your personal spaces”. It’s curated by Janek Schaefer and features 1000 different locations, by 100 different artists.
Foundsoundscape was inspired by the very first Digital Radio station in the UK, that simply played a recording of a rural location. Radio you could just leave running to add a peaceful ambience to your environment indoors. It heralded a new media paradigm, as digital broadcasting offered more capacity than requred for the first time, and that space needed filling. At the same time on TV, Channel 4 was broadcasting Big Brother live 24hours, and at night I loved to tune-in my analogue TV sets all over the house, and the shed, so I could hear the housemates gently sleeping as I worked through the night. Since then infomercials, and gambling TV have taken over, and I greatly miss that sense of real-time space, that does not demand your attention. Foundsoundscape quietly underscores your environment, by creating new ones from others.

Il volo silenzioso

Il gufo riesce a volare in perfetto silenzio.
Inaudibile anche in cuffia, nonostante debba passare a pochi centimetri da un nutrito set di microfoni (e che microfoni) in un ambiente di test già silenzioso di suo. Le sue ali muovono l’aria senza generare alcun picco.
NB: NON “alcun picco a frequenze udibili”, ma proprio nessun picco. La registrazione è una linea praticamente dritta (vedi il secondo video).
Tratto dal programma di BBC Two Natural World. Segnalato da Lucia.
In questo breve video c’è l’essenza dell’esperimento.
Qui abbiamo un video un po’ più completo con qualche commento.
The Ghost In The Mp3
Ryan Maguire, Ph.D. student in Composition and Computer Technologies al Center for Computer Music dell’Università della Virginia, ha fatto una analisi accurata su ciò che l’algoritmo di compressione dell’MP3 elimina. Il tutto nell’ambito di un progetto chiamato The Ghost In The Mp3 il cui fine è, in realtà, quello di ricavare materiale compositivo da quelli che si possono definire gli scarti dell’MP3 (quella linkata è la pagina principale, ma vedi qui per discussione dettagliata ed esempi).
Degli effetti della compressione MP3 abbiamo già parlato qui, facendo notare che, a livelli di compressione maggiori di 192 kbps (cioè da 128 in giù), la perdita di frequenze alte sia sensibile anche in brani rock, cioè non particolarmente raffinati. Sull’algoritmo di compressione MP3 vedi “La Compressione MP3“.
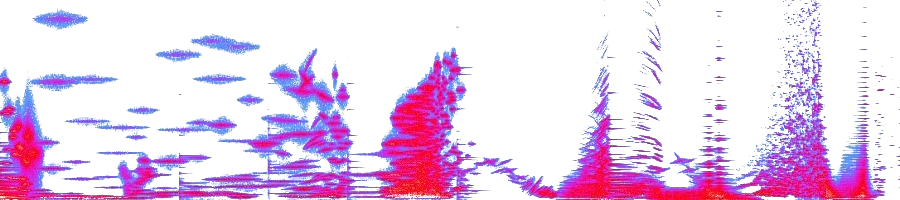
L’analisi di Maguire, però, è più profonda della mia e mette in luce perdite che potrebbero essere significative sull’intera estensione della banda. La sua analisi è concettualmente semplice. In pratica, ha confrontato gli spettrogrammi di un brano prima e dopo la compressione lavorando, ovviamente, non sulle immagini degli spettrogrammi, ma sui dati numerici ricavati dalle analisi FFT che si eseguono per realizzare le immagini.
Ecco, per esempio, tre spettrogrammi relativi al brano di Suzanne Vega “Tom’s Diner” che è per voce sola ed è spesso utilizzato come test degli algoritmi di compressione. Le prime due si riferisco a prima e dopo la compressione a 128 kbps e non mostrano differenze visibili. La terza è lo spettrogramma differenziale ottenuto confrontando i dati binari e mostra che delle differenze esistono (click immagini per ingrandire).
 |
 |
 |
A prima vista, questo risultato non mi colpisce: ho già mostrato in alcuni post che a 128 kbps c’è una differenza sensibile (vedi alla fine del post in “potrebbero interessarti anche”) e l’MP3 è una compressione con perdita, quindi qualcosa deve pur levare.
Quello che però risulta da questa comparazione è che la perdita non si limita alle alte frequenze, ma si estende su tutta la banda. Anzi, è più visibile nella parte medio-bassa della banda acustica e in alcuni punti è anche piuttosto forte. Ora bisogna capire che cosa effettivamente viene tolto, cioè quanto siano significativi quei blob che si vedono nella terza immagine.
Qui sotto potete ascoltare i tre esempi audio da soundcloud: originale, compresso e differenziale. Alzando un po’ il volume si nota come il differenziale contenga chiaramente anche una parte del cantato. Considerando che il bit rate è 128, non è una scoperta, però è un risultato interessante perché è il prodotto di una comparazione numerica precisa, non “spannometrica”.
Ora la discussione può essere impostata in modi molti diversi.
Da un punto di vista, per così dire, filosofico, è chiaro che qualsiasi riproduzione dovrebbe essere vietata e che la musica dovrebbe esistere solamente live. Considerando che le frequenze presenti negli spettri strumentali vanno ben oltre i 20.000 Hertz (vedi il post “C’è vita oltre i 20.000 Hertz!“) e che qualcuno sostiene che, anche se non le sentiamo, queste componenti hanno un qualche effetto su di noi (il che, imho, è tutto da provare), la musica registrata con gli attuali standard e riprodotta con gli attuali impianti è ben diversa dalla sua esecuzione live.
Partendo, invece, da posizioni più, diciamo, utilitaristiche, si tratta di capire quanto valore abbia la riduzione della dimensione dei file che l’MP3 assicura rispetti a ciò che va perso e qui la valutazione dipende molto dalle abitudini di ascolto di ciascuno di noi. Personalmente tengo in MP3 a 320, quindi con compressione limitata, la musica a cui tengo meno e in FLAC (compressione senza perdita) ciò che mi interessa di più, ma ho anche un bell’impianto e generalmente non ascolto con cuffiette o simili.
Invece, pur non comprando quasi più CD, ma solo da negozi online, ormai da tempo non compro musica che mi venga venduta in MP3. Come cliente, esigo sempre una registrazione non compressa o compressa senza perdita.
Virtual Acoustic Modelling
Con il termine “Virtual Acoustic Modelling” si intende la ricostruzione computerizzata dell’acustica di un ambiente. In pratica si realizza un modello acustico di un ambiente mediante il quale è possibile elaborare dei suoni e ascoltarli con la riverberazione e la risposta in frequenza di quell’ambiente.
Se l’ambiente è esistente e accessibile, la cosa è relativamente semplice perché è possibile rilevare la risposta all’impulso di quel luogo. Poi si esegue una convoluzione fra un qualsiasi suono privo di riverberazione (tipicamente registrato in camera anecoica) e la risposta all’impulso per immergere il suono in quell’ambiente (per una spiegazione più dettagliata, vedi Graziani, Riverbero mediante Convoluzione).
 La difficoltà nasce quando l’ambiente in esame non è più accessibile, per esempio è stato distrutto o è cambiato radicalmente nel corso degli anni, come nel caso dell’Abbazia di St. Mary a York, della quale rimangono solo rovine (immagine ingrandibile a lato). In questo caso è necessario stimare la risposta all’impulso dell’edificio originale, prendendo in considerazione la sua architettura in termini di volumi e materiali, servendosi di un software di simulazione per calcolare le riflessioni e l’assorbimento a varie frequenze.
La difficoltà nasce quando l’ambiente in esame non è più accessibile, per esempio è stato distrutto o è cambiato radicalmente nel corso degli anni, come nel caso dell’Abbazia di St. Mary a York, della quale rimangono solo rovine (immagine ingrandibile a lato). In questo caso è necessario stimare la risposta all’impulso dell’edificio originale, prendendo in considerazione la sua architettura in termini di volumi e materiali, servendosi di un software di simulazione per calcolare le riflessioni e l’assorbimento a varie frequenze.
Questo progetto viene portato avanti da un team dell’Università di York. In questa pagina il progetto viene descritto in dettaglio, con alcuni esempi.
Resonant Architecture
ARCHITECTURE AS AN INSTRUMENT
VIDEO DOCUMENTARIES ABOUT ARCHITECTURAL SPACES SET INTO VIBRATION
Since 2006, the Art of Failure collective has been sending bass frequencies into remarkable architectural structures. These experiences establish a dialog between architecture, the structures’ spatial components, and their geographic context – revealing building’s specific acoustic and vibrating qualities.
A projet by: Art of Failure
Art direction: Nicolas Maigret
Conception: Nicolas Maigret, Jeremy Gravayat, Nicolas Montgermont
Video / editing: Jérémy Gravayat
Sound recordings / Mixing: Yann Leguay
Sound installations: Nicolas Maigret, Nicolas Montgermont
Supports: Arcadi, Cnc Dicream, Cnap, Futur En Seine, Ville De Clichy – Production: Ososphere, Seconde Nature, Sonic Protest, Ars Longa, Gaite Lyrique
More on resonantarchitecture.com

The Harmonics of Real Strings
 In questa composizione di John Lely per violoncello solo, l’esecutore esegue un lunghissimo glissando su una sola corda, dal capotasto fino al ponte, esercitando una leggera pressione per ottenere gli armonici, da cui il titolo The Harmonics of Real Strings (2006/2013). Nel CD edito da Another Timbre si possono ascoltare quattro versioni del brano, una per ciascuna corda del violoncello. L’esecutore è Anton Lukoszevieze.
In questa composizione di John Lely per violoncello solo, l’esecutore esegue un lunghissimo glissando su una sola corda, dal capotasto fino al ponte, esercitando una leggera pressione per ottenere gli armonici, da cui il titolo The Harmonics of Real Strings (2006/2013). Nel CD edito da Another Timbre si possono ascoltare quattro versioni del brano, una per ciascuna corda del violoncello. L’esecutore è Anton Lukoszevieze.
Nella stessa pagina trovate anche un’intervista con il compositore. Nella pagina di John Lely su Soundcloud potete ascoltare anche le versioni per violino e per contrabbasso.
I tempi sono cambiati
Bologna. Il 23 giugno del 1643, su richiesta dei professori e studenti dell’Università fu avanzata al Comune una perentoria protesta affinché fosse fatto divieto al transito per i carri attorno all’Archiginnasio per consentire agli studenti di studiare nel dovuto silenzio. L’istanza fu accolta.
[Tratto da Sounday Times, Il rumore e la città – considerazioni sul convegno la città nel rumore il rumore nella città]
Questo non per fare un elogio dei bei tempi andati, ma solo per sorridere un po’ 🙂 . In fondo parliamo di quasi 400 anni fa.
Feedback Babies
Un’altra installazione di Darsha Hewitt.
I Fisher-Price Nursery Monitor sono gli antenati (ca. 1983) degli odierni baby monitor con cui si può ascoltare il pargolo a distanza, anche via cellulare. L’ingombrante modello degli anni ’80 era costituito da un trasmettitore e da un ricevitore operanti su frequenze radio. Darsha Hewitt ha trovato un modo di riutilizzare questo dispositivo ormai obsoleto.
The Fisher-Price Nursery Monitor (circa 1983) was a low watt household radio set originally intended to “let parents be in two places at once” by broadcasting the cries of a baby in distress to a mobile receiver accompanying a parent outside of earshot. However, when in very close proximity these devices produce audible feedback that sounds uncannily like whimpering electronic babies. Feedback Babies is an electromechanical sound apparatus that makes use of slow moving motors to automate these transmitters in order to create nuanced feedback patterns.
Cities & Memory
 Cities & Memory è l’ennesima mappa sonora dell’orbe terracqueo, ma è anche una delle più curate perché ha varie sezioni, ordinamenti e collezioni.
Cities & Memory è l’ennesima mappa sonora dell’orbe terracqueo, ma è anche una delle più curate perché ha varie sezioni, ordinamenti e collezioni.
Cities and Memory is a global field recording & sound art work that presents both the present reality of a place, but also its imagined, alternative counterpart – remixing the world, one sound at at time.
Every faithful field recording document on the sound map is accompanied by a reworking, a processing or an interpretation that imagines that place and time as somewhere else, somewhere new. The listener can choose to explore locations through their actual sounds, or explore interpretations of what those places could be – or to flip between the two different sound worlds at leisure.
There are currently [dec 2014] more than 350 sounds featured on the sound map, spread over 23 countries.The sounds cover parts of the world as diverse as the hubbub of San Francisco’s main station, traditional fishing women’s songs in Lake Turkana, the sound of computer data centres in Birmingham, spiritual temple chanting in New Taipei City or the hum of the vaporetto engines in Venice.
The sonic reimaginings or reinterpretations can take any form, and include musical versions, slabs of ambient music, rhythm-driven electronica tracks, vocal cut-ups, abstract noise pieces, subtle EQing and effects, layering of different location sounds and much more.
The project is completely open to submissions from field recordists, sound artists, musicians or anyone with an interest in exploring sound worldwide – more than 60 contributors have got involved so far.
Cities and Memory takes its name and original inspiration from Italo Calvino’s book Invisible Cities, which explores how people can experience the same place in dramatically different ways.
L’Illuminazione
The Quiet Ensemble è un collettivo artistico formato da Fabio Di Salvo & Bernardo Vercelli.
 Nella loro installazione The Enlightenment ogni lampada è dotata di un sensore che ne cattura il campo elettromagnetico. Il ronzio che si genera viene inviato al computer e poi all’impianto di amplificazione. Dalle note degli autori (di seguito), non è chiaro se il suono venga elaborato in qualche modo o semplicemente mixato e amplificato.
Nella loro installazione The Enlightenment ogni lampada è dotata di un sensore che ne cattura il campo elettromagnetico. Il ronzio che si genera viene inviato al computer e poi all’impianto di amplificazione. Dalle note degli autori (di seguito), non è chiaro se il suono venga elaborato in qualche modo o semplicemente mixato e amplificato.
Un concerto in cui l’orchestra classica e gli strumenti vengono sostituiti da un set up elettrico. Al posto dei violini suonano i neon, a sostituire i tamburi sono le lampade stroboscopiche e al posto dell’arpa vediamo un faro teatrale che illumina il pubblico. Saranno quindi luci di ogni genere a sostituire gli strumenti musicali.
Ogni tipo di lampada ha un suono proprio, costituito dall’amplificazione della propria “ronza”, quel rumorìo di disturbo che solitamente viene eliminato durante concerti e spettacoli, generato dall’energia elettrica che alimenta ogni singolo faro.
Le frequenze che emettono le luci si sentono sotto pelle e variano in base alla dimensione ed al tipo d’illuminazione della lampada.
Per estrapolare il suono nascosto delle luci viene utilizzata una bobina di rame.
Ogni lampada ha un proprio sensore che ne percepisce il suono; quando la lampada irradia la luce, il sensore ne cattura il campo elettromagnetico presente intorno al flusso energetico e il rumore viene trasportato attraverso dei cavi microfonici al computer per poi uscire direttamente dall’impianto audio rivelando il “concerto invisibile”.
Il malfunzionamento dell’iperdrive del Millennium Falcon
 Ben Burtt, sound designer, spiega come è stato creato il suono, in parte comico, del malfunzionamento dell’iperdrive del Millennium Falcon in Star Wars.
Ben Burtt, sound designer, spiega come è stato creato il suono, in parte comico, del malfunzionamento dell’iperdrive del Millennium Falcon in Star Wars.
Il suono in questione è il missaggio di otto suoni diversi, quasi tutti prodotti da false partenze o spegnimento di motori o ingranaggi. Il che dimostra, ancora una volta, che, per fare il sound designer, non serva poi essere degli esperti in tecnologie, quanto essere creativi e soprattutto aver passato così tanto tempo ad ascoltare e sperimentare con il suono da riuscire a capire quale effetto può fare un certo suono, magari iper-amplificato o con la velocità cambiata.
In effetti, in questo esempio, la tecnologia arriva, al massimo, a un mixer e a un registratore a velocità variabile. E di questo è fatto il 98% degli effetti cinematografici più famosi (in Star Wars fa eccezione il suono di R2D2 creato con un sintetizzatore analogico ARP 2600).
Ben Burtt ha creato quasi tutti i suoni di Star Wars mediante missaggi. Per la voce di Chewbacca, per esempio, ha registrato centinaia di suoni di orsi, trichechi, leoni e altri animali. Poi ha cercato di catalogarli in base alle emozioni che trasmettevano e fondendoli insieme, ha creato il linguaggio di Chewbacca.
È interessante, poi, sentire come ha creato il famosissimo suono della spada laser:
Burtt said he could “hear the sound in his head.” At the time, he was still a graduate student at USC and was working as a projectionist. The old projector had an interlocked motor which, when idle, made a “wonderful humming sound.” Burtt recorded it, and it became the basis of the lightsaber sound. But it wasn’t enough — he needed a buzzing sound, and he actually found it by accident. Walking by television set with a live microphone, the microphone picked up the transmission from the unit and produced a buzz. Burtt loved it, recorded it, and combined it with the projector motor, creating a new sound that became the basic lightsaber tone. To achieve the aural effect of a lightsaber moving, he played the hum out of a speaker and waved a microphone by it; doing so created the fascimile of a moving sound, and in this case, the sound of a Jedi or Sith wielding a weapon in battle.
Il tutto fa pensare alla vecchia conferenza di Stockhausen su scoperta e invenzione, la cui essenza è che in campo musicale (e sonoro), alcune cose accadono perché sono state progettate, mentre altre si scoprono per puro caso, spesso lavorando a qualcos’altro.
Suonerie minimaliste
 Alcune suonerie minimaliste sono disponibili da questa pagina.
Alcune suonerie minimaliste sono disponibili da questa pagina.
Ottime recensioni da Gizmodo e Wired. Effettivamente se fossero tutte così, viaggiare in treno sarebbe piacevole.
Corde vibranti
Simpatica idea quella di mettere un cellulare dentro la cassa della chitarra per filmare le corde in vibrazione. Naturalmente i 25/30 fps del video non ci stanno dietro, però la forma che prende la corda vibrante si vede bene in parecchi casi.
Su You Tube trovate parecchi video di questo tipo. Ecco alcuni esempi.
Acousmographe
L’Acousmographe dell’istituto di ricerca francese INA/GRM è un software per l’analisi e la rappresentazione della musica elettroacustica, e per estensione, di qualsiasi fenomeno sonoro registrato.
Il suo sviluppo è un progetto a lungo termine che nasce dalla necessità sentita da compositori e musicologi di disporre di strumenti per la trascrizione di musiche non scritte, mediante rappresentazioni grafiche e annotazioni testuali sincronizzate con l’ascolto e con le tecniche usuali di rappresentazione del segnale (ampiezza – analisi spettrale).
Disponibile sia per Mac che per Windows, è arrivato alla versione 3.7 ed è scaricabile qui.
Esiste anche un buon manuale in italiano (pdf) a questo link. Si può anche visualizzarlo in linea sul blog di Alex Di Nunzio.
 |
 |
The Only Good System…
Seebad Prora (Bagno di Prora) è una località balneare progettata e in parte edificata, sull’isola tedesca di Rügen (Mar Baltico) tra il 1935 e il 1939.
Scopo del progetto, concepito dall’organizzazione nazionalsocialista Kraft durch Freude (KdF) era la costruzione di una località balneare che potesse accogliere 20.000 villeggianti.
Dopo l’inizio della seconda guerra mondiale i lavori di costruzione vennero interrotti, oggi ne rimane la parte centrale del progetto complessivo, il cosiddetto colosso di Prora composto da otto edifici identici e affiancati che si estendono lungo la costa per un totale di 4,5 km e che attualmente, benché tutelati in quanto monumento storico, si stanno rapidamente degradando. [wikipedia]
Su uno degli edifici, una mano ignota ha tracciato questa significativa scritta (click to enlarge).

NASA Sounds
 La NASA ha aperto un proprio canale su SoundCloud e la cosa interessante è che i suoni ivi contenuti possono essere utilizzati senza vincoli a scopo educativo o informativo, ma anche a scopo commerciale, a patto che l’ente spaziale non sia coinvolto in nessun modo (ovvero, non puoi, per esempio, farti pubblicità dicendo che il tuo pezzo è fatto con suoni NASA; if the NASA material is to be used for commercial purposes, especially including advertisements, it must not explicitly or implicitly convey NASA’s endorsement of commercial goods or services; vedi qui).
La NASA ha aperto un proprio canale su SoundCloud e la cosa interessante è che i suoni ivi contenuti possono essere utilizzati senza vincoli a scopo educativo o informativo, ma anche a scopo commerciale, a patto che l’ente spaziale non sia coinvolto in nessun modo (ovvero, non puoi, per esempio, farti pubblicità dicendo che il tuo pezzo è fatto con suoni NASA; if the NASA material is to be used for commercial purposes, especially including advertisements, it must not explicitly or implicitly convey NASA’s endorsement of commercial goods or services; vedi qui).
Il contenuto è vario. Si va dagli annunci storici (“Houston, we’ve had a problem” o “The Eagle has landed“) fino a suoni di razzi, beep dei satelliti, emissioni radio registrate nei dintorni dei pianeti e convertite in audio.
Quello che segue è solo un estratto. Buon ascolto.
Radio Aporee
Il progetto Radio Aporee ::: Mappe Sonore Collettive nasce nel 2006 con l’intento di sviluppare una cartografia sonora con geolocazione di suoni provenienti da vari ambienti, da quelli più o meno urbanizzati fino alla natura.
La mappa è qui. All’inizio si apre su un suono (cerchio rosso). Zoomate all’indietro fino a vedere altri cerchi rossi che indicano la locazione di altri suoni (vedi immagine sotto).
È possibile aggiungere altri suoni alla mappa cliccando sulla locazione dove si vuole piazzare il suono.

World Sound Mix
Il World Sound Mix mixa senza sosta suoni da tutto il mondo. I suoni provengono dall’archivio del FreeSound Project.

Sonification Handbook
 Il Sonification Handbook (AA.VV., a cura di Thomas Hermann, Andy Hunt, John G. Neuhoff) è scaricabile gratuitamente (e legalmente) in versione PDF da questa pagina (guardate nella colonna di destra “download the book”) da cui è anche acquistabile in versione stampata. È possibile anche scaricare i singoli capitoli.
Il Sonification Handbook (AA.VV., a cura di Thomas Hermann, Andy Hunt, John G. Neuhoff) è scaricabile gratuitamente (e legalmente) in versione PDF da questa pagina (guardate nella colonna di destra “download the book”) da cui è anche acquistabile in versione stampata. È possibile anche scaricare i singoli capitoli.
Questo libro è una presentazione introduttiva, ma completa delle aree chiave della ricerca nei campi interdisciplinari di sonificazione e visualizzazione uditiva (auditory display). I capitoli sono scritti da esperti e coprono una vasta gamma di temi centrali. Possono essere letti dall’inizio alla fine, o indipendentemente l’uno dall’altro secondo necessità (come il menu di un ricco buffet).
La sonificazione trasmette informazioni utilizzando suoni non vocali. Ascoltare i dati sotto forma di suono o rumore può essere un’esperienza sorprendentemente nuova con diverse applicazioni che vanno da nuove interfacce per i non vedenti all’analisi dei dati in molti campi scientifici.
Questo testo fornisce una solida introduzione al campo della visualizzazione uditiva (auditory display), delle tecniche per sonificazione, delle tecnologie adeguate a sviluppare algoritmi di sonificazione, e delle aree di applicazione più promettenti. Il libro è accompagnato daun’archivio online di esempi sonori.
Hooke
 Hooke è una start-up che ha avuto l’idea di inserire due piccoli microfoni nei padiglioni di una cuffia wireless. In questo modo si possono fare delle registrazioni che si avvicinano alla tecnica binaurale.
Hooke è una start-up che ha avuto l’idea di inserire due piccoli microfoni nei padiglioni di una cuffia wireless. In questo modo si possono fare delle registrazioni che si avvicinano alla tecnica binaurale.
Doco “si avvicinano” perché, nelle registrazioni binaurali, i microfoni devono essere piazzati all’interno del padiglione auricolare, in pratica all’inizio del canale uditivo. Infatti viene costruita una testa artificiale che ha la forma stilizzata di una testa umana, con i padiglioni auricolari accuratamente riprodotti e i microfoni vengono inseriti all’interno dei padiglioni. La presenza della testa serve a mascherare le onde sonore nello stesso modo in cui lo fa una testa umana e tutto il sistema arriva a costare parecchio. Il KU 100 di Neumann, per esempio, costa circa € 7000.
Esistono anche sistemi più economici che, invece di riprodurre l’intera testa, si limitano ai padiglioni auricolari, con prezzi decisamente inferiori, ma il solo padiglione non basta perché si perde l’effetto schermante della testa che crea le differenze interaurali di ampiezza e tempo tipiche del sistema percettivo umano (vedi Il suono nello spazio dal mio corso di acustica).
L’idea di Hooke è molto buona perché in questo modo non c’è bisogno di costruire una testa artificiale, ma si usa la testa umana di chi indossa le cuffie. Di contro c’è il fatto che, il microfono, essendo sul padiglione della cuffia, per quanto piccolo sia, difficilmente può captare il suono esattamente come quando entra nel canale uditivo che inizia all’interno del padiglione. Ciò non toglie che questo oggetto permette di avvicinarsi alla registrazione binaurale con costi risibili rispetto a quelli dei sistemi professionali. Il prezzo annunciato, infatti, è inferiore a $ 120. Aspettiamo e vedremo.
Questo è il sito ufficiale e qui abbiamo un demo su vimeo.
Hooke: Wireless 3D Audio Headphones from Hooke Audio on Vimeo.
UPGRADE
Grazie per avermi segnalato un prodotto praticamente identico che esiste già: le cuffie Roland CS-10EM. Si trovano in vendita a circa € 100. L’unica differenza con Hooke è che non sono wireless, ma hanno il cavo (il che, per la qualità della registrazione, è meglio). A questo punto sembra proprio che non sia stato Hooke ad avere l’idea.
Il canto della cometa
Ok. Dimenticate il titolo aulico. Quello di cui parliamo è un fenomeno scientifico che comunque ha anche dei risvolti audio e ci offre l’occasione di parlare di una delle più affascinanti missioni spaziali degli ultimi anni.
Rosetta è una missione spaziale sviluppata dall’Agenzia Spaziale Europea e lanciata nel 2004. L’obiettivo ultimo della missione è lo studio della cometa 67P/Churyumov-Gerasimenko, una cometa periodica che ritorna ogni 6.45 anni terrestri.
La missione è formata da due elementi: la sonda vera e propria Rosetta e il lander Philae. Quest’ultimo è destinato a staccarsi dalla sonda e atterrare sul nucleo della cometa, di cui la sonda ha già inviato splendide foto. Il distacco è avvenuto proprio oggi 12/11 e il lander sta scendendo verso il nucleo (incrociamo le dita).
La parte audio della faccenda è questa. Ovviamente la sonda trasporta molti strumenti per studiare da vicino la cometa. Cinque di questi costituiscono il cosiddetto Rosetta’s Plasma Consortium (RPC) e servono a studiare l’ambiente di plasma che circonda la cometa (il plasma è uno stato della materia che appare come un gas elettricamente conduttivo che circonda i campi magnetici e le correnti elettriche).
Già in Agosto, l’RPC ha scoperto che il campo magnetico della cometa ha una oscillazione con frequenza intorno ai 40-50 millihertz. Ora, qualsiasi oscillazione più o meno periodica può essere trasformata in suono. In questo caso il problema è che la frequenza è troppo bassa per essere udibile. Le frequenze più basse che siamo in grado di percepire stanno intorno a 20 Hz, mentre qui abbiamo a che fare con 0.05 Hz.
Il problema si può risolvere trasponendo (ovvero accelerando) il tutto di circa 10000 volte. Così 0.05 Hz diventano 500 Hz che sono perfettamente ascoltabili e il suono che ne esce è questo:
Ecco un’immagine del nucleo della cometa (il piccolo 747 che vedete al centro non è alieno; è lì per confronto; clicca per ingrandire)
 Una nota finale. Prima di delirare con toni mistici intorno al canto della cometa, rendetevi conto che qualsiasi fenomeno periodico può essere convertito in suono. Per esempio, la rotazione terrestre è periodica. Il giorno solare medio dura circa 24 ore, cioè 86400 secondi. Di conseguenza. dato che la frequenza è l’inverso del periodo, esso ha una frequenza di 0.000011574 Hz, troppo bassa per sentirla, ma basta trasporla di 24 ottave per avere circa 194.18 Hz, che corrispondono a una nota perfettamente udibile: un Sol appena calante (con La = 440 Hz).
Una nota finale. Prima di delirare con toni mistici intorno al canto della cometa, rendetevi conto che qualsiasi fenomeno periodico può essere convertito in suono. Per esempio, la rotazione terrestre è periodica. Il giorno solare medio dura circa 24 ore, cioè 86400 secondi. Di conseguenza. dato che la frequenza è l’inverso del periodo, esso ha una frequenza di 0.000011574 Hz, troppo bassa per sentirla, ma basta trasporla di 24 ottave per avere circa 194.18 Hz, che corrispondono a una nota perfettamente udibile: un Sol appena calante (con La = 440 Hz).
C’è vita oltre i 20.000 Hertz!
In realtà lo sapevamo già tutti (almeno noi che lavoriamo sull’audio digitale), ma, visto che noi umanoidi sentiamo solo fino a circa 20.000 Hertz (e solo se abbiamo 10 anni e le orecchie lavate), spesso non ci pensiamo.
E così, quando circa 20 anni fa, munito di una scheda audio e un microfono in grado di acquisire il suono con una banda passante superiore ai 22.000 Hz (frequenza massima del CD e degli impianti Hi-Fi)il che, per la scheda, significa un campionamento ben maggiore dei classici 44100/48000 Hertz, oggetti piuttosto rari a quell’epoca) James Boik, del Caltech, ha analizzato lo spettro di alcuni strumenti musicali scoprendovi frequenze superiori ai 50.000 Hertz, tutti sono rimasti colpiti.
Due parole di spiegazione per i non addetti. La banda di frequenza riprodotta normalmente nell’audio digitale va da 0 a 22050 Hz per il CD e 24000 Hz per il DVD. Il che, considerando che gli umanoidi sentono fino a circa 20000 Hz quando sono bambini e crescendo perdono le frequenze alte (il 70enne medio non arriva a 15000 Hz), va bene.
Ora, per registrare audio che arriva a 20000 Hz, una apparecchiatura audio digitale deve lavorare a una frequenza molto superiore. Per la precisione, il doppio. Quindi, per registrare un suono per noi acutissimo a 20000 Hz, una scheda audio deve lavorare almeno a 40000 Hz. Il che significa che deve trattare almeno 40000 numeri al secondo per ogni canale di audio (80000 per un segnale stereo, 240000 per un 5+1) .
È una situazione analoga a quella del cinema. Un film non è altro che una sequenza di fotografie, cioè immagini fisse. Per avere la sensazione del movimento occorre superare la soglia oltre alla quale il nostro sistema occhio-cervello non è più in grado di percepire le singole immagini, ma ognuna si fonde con la successiva, dando l’illusione del movimento. Per la vista, questa soglia è di circa 25 immagini al secondo (è la frequenza del PAL cioè la televisione europea (lo standard americano NTSC, invece, va a poco meno di 30)). Tuttavia si è visto che con frequenze maggiori l’immagine è più nitida e la qualità è superiore, soprattutto nel caso di grandi schermi. Il cinema, quindi, adotta frequenze intorno ai 50/60 Hz e così ormai fanno i monitor da computer e le TV digitali.
Torniamo all’audio. La verità e che, se consideriamo che il DO più alto del pianoforte emette una nota la cui fondamentale è 4186 Hz (accordato sul LA = 440), basta arrivare alla quinta componente armonica per superare i 20.000 Hz e di armonici ce ne sono ben più di 5. Di conseguenza, tutti sapevamo che l’estensione spettrale delle note alte degli strumenti musicale superava la fatidica soglia del nostro sistema percettivo, ma nessuno immaginava che potesse accadere anche con note non così alte.
E invece la ricerca di Boik mostra, per esempio, che una tromba che suona un SIb con fondamentale a 465.4 Hz emette componenti armoniche che superano i 50 kHz oltrepassando la 100ma armonica con ampiezza, sì, bassa, ma non proprio banale.
Cliccate sulla figura qui sotto per ingrandirla e leggere la didascalia. L’articolo intero è qui o qui.

Korg MS-20 Kit
 Il Korg MS-20 è tornato in versione Ikea, ovvero scatola di montaggio prodotta dalla stessa Korg. L’originale è rimasto in produzione dal 1978 al 1983 ed è ormai diventato un pezzo da collezione venduto a cifre che arrivano a € 1600.
Il Korg MS-20 è tornato in versione Ikea, ovvero scatola di montaggio prodotta dalla stessa Korg. L’originale è rimasto in produzione dal 1978 al 1983 ed è ormai diventato un pezzo da collezione venduto a cifre che arrivano a € 1600.
Cliccate l’immagine per un ingrandimento mega.
Finora era disponibile una replica prodotta sempre da Korg, ma a dimensioni ridotte di circa il 14% (il cosiddetto MS-20 mini) al prezzo di circa € 600, mentre questa nuova versione è a dimensioni intere.
Secondo i produttori, anche la circuiteria analogica originale è stata replicata accuratamente utilizzando, per quanto possibile, gli stessi componenti e sostituendo quelli non più in produzione con altri che garantiscono la sonorità tradizionale.
Un dato importante riguarda i filtri. Nel corso della produzione, infatti, il disegno dei filtri era stato cambiato. Il primo tipo aveva una caratteristica distorsione e andava facilmente in auto-oscillazione. Qualche anno dopo era stato sostituito da un filtro più dolce e facile da controllare, ma meno “cattivo”. Questa versione dispone di entrambe le versioni dei filtri e consente di passare dall’una all’altra grazie a un jumper sul circuito. Lo switch, quindi, è interno (una cosa da nerd).
Sono state aggiunte anche una porta MIDI IN e una USB con funzioni di MIDI IN e OUT.
Il prezzo, però, sembra elevato: si parla di circa $ 1400 con disponibilità a Marzo. Ecco il sito del produttore e un divertente video promozionale. Effettivamente montarselo deve essere una goduria.
Unknown Pleasures 3D model
Se qualcuno ha una stampante 3D e vuole stamparsi un bel modellino del famoso sonogramma di Unknown Pleasures dei Joy Division può scaricare i dati da qui.
Nella foto mancano elementi di confronto, ma è piccolo: solo 10 cm. Un bel soprammobile.

Linguaggi fischiati
Sono rari ma esistono. I linguaggi composti da fischi sono tipici di alcune località con caratteristiche che rendono difficili i contatti ravvicinati fra le persone. Un esempio sono i luoghi molto montagnosi e frastagliati, dove la gente può vedersi da lontano, ma per arrivare a contatto diretto deve camminare un bel po’.
Di conseguenza, per scambiare due parole con il tipo che vedi sull’altro versante, bisognerebbe urlare, invece, in alcuni luoghi, si è sviluppata una forma di comunicazione basata su fischi. A pensarci, anche Venezia è un posto così. Capita spesso di vedere qualcuno che conosci, solo che, invece di essere dall’altra parte della strada, è dall’altra parte del canale e il ponte più vicino è almeno a 200 metri, nella direzione opposta a quella in cui stai andando.
Bene, a Venezia non è successo, ma in Messico, nel nord-est della regione di Oaxaca, è possibile sentire uno dei rari esempi di linguaggio basato sui fischi. Questa lingua non sostituisce quella parlata, che peraltro è complessa perché, pur facendo tutti parte della stessa famiglia linguistica, quella Chinantec, nella zona esistono almeno 14 dialetti mutualmente inintelligibili. I fischi si pongono, invece, come una forma di comunicazione parallela, utilizzata quando le persone si vedono, ma non possono avvicinarsi a causa della natura montuosa del terreno.
In questo video ne sentite un esempio: si tratta di una conversazione cordiale fra due agricoltori che sono al lavoro in due appezzamenti di terreno. Si vede anche la versione scritta della conversazione.
Un altro luogo in cui si è sviluppata questa forma di comunicazione è La Gomera, un’isola delle Canarie. Qui abbiamo un video in cui si vede un buon esempio a partire da 5’35”.
Il suono delle auto elettriche
Una delle sfide dei sound designer è la progettazione del suono delle auto elettriche. Infatti, per una popolazione abituata al fatto che le auto fanno rumore, il fatto che il motore elettrico emetta un suono quasi inaudibile è un rischio che fa lievitare notevolmente il numero degli investiti.
È stato dimostrato che il fatto di non sentire alcun rumore di auto provoca un drastico abbassamento di attenzione nel pedone che si appresta ad attraversare una strada, soprattutto se ad alto traffico. Così, anche con l’avvento dell’auto elettrica, non potremo godere della pace in città. Il rischio giustifica l’idea di dotare le auto elettriche di un suono sintetico.
Dal 2019 esiste anche un’ordinanza UE che stabilisce l’obbligo per le auto elettriche di emettere un suono (AVAS: Acoustic Vehicle Alert System). È interessante notare che, secondo la Commissione Europea, il suono dovrebbe essere rappresentativo dei cambiamenti di stato del veicolo cioè, per esempio, suggerire che il veicolo sta accelerando o rallentando e la retromarcia dovrebbe avere un suono diverso.
Suoni della natura su You Tube
You Tube si rivela ogni giorno più impressionante. C’è gente che carica ore e ore di field recording (che non pone nemmeno problemi di copyright).
Cercando “sounds of nature” (senza virgolette) questi video saltano fuori e se si mette anche la chiave -music (con il meno davanti), si eliminano tutte quelle sconcezze formate da suoni naturali con sopra nefanda musichetta ambient.
Occorre solo stare attenti alla frequenza di campionamento: alcuni, per risparmiare spazio e quindi tempo di caricamento, la riducono a 22050, ma altri riescono a tenerla a 44100 anche su video lunghi.
Visto il tempo di questi giorni, non ce sarebbe bisogno, comunque, a titolo di esempio, ecco 10 (dieci!) ore di pioggia e tuoni (magari l’estate prossima vi viene buono…)
Zimoun
Zimoun è svizzero. Crea sculture e installazioni in movimento in cui la componente sonora è essenziale.
Nei suoi lavori, il movimento di una gran quantità di semplici oggetti industriali mossi da piccoli motori crea un flusso sonoro granulare caotico. Come nel Poema Sinfonico per 100 Metronomi di Ligeti, anche qui il flusso è creato dalla sovrapposizione sfasata di molti elementi semplici, tutti uguali, ognuno dei quali ha una pulsazione ritmica regolare.
Profetico
Nell’autunno del 1888 George Gouraud fece, a Londra, una serie di dimostrazioni della nuova invenzione di Edison: il fonografo, capace di registrare il suono su cilindri di paraffina. Dopo le demo, Gouraud registrava le reazioni dei presenti su cilindri da inviare ad Edison.
Uno dei presenti era il compositore Arthur Sullivan (1842-1900). Nel suo messaggio disse, fra l’altro:
For myself, I can only say that I am astonished and somewhat terrified at the results of this evening’s experiment — astonished at the wonderful power you have developed, and terrified at the thought that so much hideous and bad music may be put on record forever.
Trad. mia
Per quel che mi riguarda, posso solo dire di essere sbalordito, ma anche un po’ spaventato dai risultati dell’esperimento di ieri sera — sbalordito dal fantastico potere che avete sviluppato e spaventato al pensiero di quanta orrenda e cattiva musica potrà essere registrata per sempre.
Fonte: wikipedia
Vibroy
La compagnia coreana Xenics ha prodotto un simpatico ordigno, chiamato Vibroy, che serve a trasmettere un’onda sonora a un qualsiasi oggetto utilizzabile come cassa armonica, con il risultato di rendere l’onda udibile. È lo stesso principio per cui il diapason diventa udibile quando lo si posa sulla cassa del pianoforte o della chitarra.
In pratica, Vibroy si collega, via minijack, a un player (per es. un lettore di MP3). Poi si posa il mini-speaker che sta all’altro capo del filo su un oggetto qualsiasi. In questo modo Vibroy trasmette la vibrazione all’oggetto con cui è in contatto che diventa un altoparlante.
Naturalmente la qualità dell’audio è fortemente influenzata dalla natura dell’oggetto usato come speaker e dalla sua capacità di vibrare. I vari materiali, infatti, si comportano diversamente: un bicchiere di vetro, per esempio, riprodurrà solo le frequenze alte, mentre un oggetto di legno avrà uno spettro più vasto.
Ecco qualche demo.
Ora, visto che in giro se parla come una genialata, vediamo di chiarire…
Punto primo, con un mini-speaker del genere come sorgente, questo coso avrà, in partenza, un range di frequenze molto limitato. A occhio, non va sotto i 200/300 Hz e non va sopra i 10000: i bassi e gli acuti vanno persi.
Secondo, la risposta in frequenza di un oggetto qualsiasi è ben lontano dall’essere anche vagamente piatta. Di conseguenza quello che si sente ha poco a che fare con quello che i musicisti hanno cercato di realizzare. Tuttavia, è molto divertente e anche istruttivo sentire la risposta in frequenza dei vari oggetti.
Infine, non è l’unico sistema del genere. Su YouTube se ne vedono altri, praticamente uguali. Un significativo passo avanti verso il lo-fi generalizzato.
Frodi Musicali
Dopo la discussione, peraltro molto interessante e per me, fruttuosa, sulla paternità delle opere di Scelsi, ho cercato un po’ per vedere se potessero esistere altri casi paragonabili.
Quando ho cominciato pensavo che in musica non esistessero molte situazioni del genere, almeno in tempi recenti (nell’antichità chissà cosa può essere successo), a meno di non scendere nel campo della musica di consumo nel senso stretto del termine dove è risaputo che gli individui che si presentano in pubblico suonano sempre in playback e sono solo dei front-men perché in realtà gli esecutori sono altri (tipicamente dei session men).
Nella musica classica, a mio ricordo, c’erano solo due casi di una certa importanza, ma entrambi riguardavano esecutori, non compositori, ed entrambi erano delle frodi consapevoli (mi riferisco al caso Joyce Hatto e a quello Schwarzkopf – Flagstad, con alcune note sostituite in una incisione). Invece è bastato cercare un po’ per trovarne parecchi:
Henri Casadesus (1879 – 1947) era violista ed editore musicale, fratello di Marius che a sua volta era lo zio del famoso pianista Robert Casadesus e prozio di Jean Casadesus. Egli fondò la Société des Instruments Anciens con Camille Saint-Saëns nel 1901. La società, che operò tra il 1901 ed il 1939, fu un quintetto di esecutori che suonavano strumenti antichi come la viola da gamba o la viola d’amore.
Il quintetto di dedicò alla riscoperta di opere di musicisti del passato non più eseguite da secoli. Si scoprì poi, che diversi pezzi attribuiti a famosi musicisti del passato, erano invece delle loro composizioni. L’Adélaïde Concerto, da loro attribuito a Wolfgang Amadeus Mozart, era stato scritto da Marius Casadesus.
Sembra invece che Henri fosse il compositore del “Concerto in re maggiore per Viola” attribuito a Carl Philipp Emmanuel Bach, descritto da Rachel W. Wade nell’appendice B del suo Keyboard Concertos of Carl Philipp Emmanuel Bach. Questo concerto apparve nel 1911 in una edizione russa, presumibilmente “trascritta…per piccola orchestra da Maximilian Steinberg,” e venne poi eseguita da direttori come Darius Milhaud e Serge Koussevitsky, e registata da Felix Prohaska e Eugene Ormandy. Nel 1981, Wade scrisse: “al giorno d’oggi, il più eseguito concerto di C.P.E. Bach non è stato scritto la lui.”
Henri è anche accreditato di un concerto di Handel e di un concerto di J.C. Bach, entrambi per viola. Questi ultimi vengono oggi adoperati nell’insegnamento del metodo suzuki per la viola, e vengono detti “The Handel/Casadesus Concerto” e “The J.C. Bach/Casadesus Concerto”.
Si passa, poi a Gaspar Cassadò (1897 – 1966), violoncellista e compositore spagnolo, ricordato perché alcune parti del suo Concerto per violoncello in RE min. e della Suite per Cello solo erano in realtà trascrizioni o rielaborazioni di brani altrui (Ravel, Kodaly), ma questo è un peccato veniale. Cassadò ha scritto molte trascrizioni e variazioni su opere altrui in modo non fraudolento. Tuttavia si è attribuito anche molti brani scritti alla maniera di… che forse lo sono un po’ troppo.
François-Joseph Fétis (1784 – 1871) è stato un musicologo, compositore e docente belga. Autore di parecchi “scherzi” (non nel senso della forma musicale), scrisse un concerto per liuto, peraltro eseguito anche da Sor, attribuendolo a Valentin Strobel.
Ma quello che ha fatto il colpo più grosso è senz’altro il musicologo italiano Remo Giazotto (1910 – 1998) che fu un famoso esperto di Albinoni, al punto tale da scrivere e attribuirgli il celeberrimo Adagio in SOL minore, noto, appunto, come Adagio di Albinoni.
Giazotto dichiarò di essersi limitato a “ricostruire” l’Adagio sulla base di una serie di frammenti di Tomaso Albinoni che sarebbero stati ritrovati tra le macerie della biblioteca di Stato di Dresda – l’unica biblioteca a possedere partiture autografe albinoniane – in seguito al bombardamento della città avvenuto durante la seconda guerra mondiale. I frammenti sarebbero stati parte di un movimento lento di sonata (o di concerto) in sol minore per archi e organo.
In verità, a partire dal 1998, anno della morte di Remo Giazotto, l’Adagio è emerso essere una composizione interamente originale di quest’ultimo, giacché nessun frammento o registrazione è stato mai trovato in possesso della Biblioteca Nazionale Sassone.
Secondo wikipedia, Giazotto è fortemente contestato dagli odierni studiosi di musica barocca, perché più volte accusato di aver prodotto dei veri e propri falsi, specie in ambito vivaldiano.
David Byrne at the Roundhouse
In occasione del suo passaggio alla Roundhouse di Londra (7-31 Agosto), abbiamo una immagine un po’ più accurata dell’installazione Playing the Building di David Byrne di cui abbiamo parlato in febbraio.
It’s all mechanical. There’s no speakers, there’s no electronics, or any of that modern rubbish.
È un po’ buffo che Byrne chiami “rubbish” quello con cui ha giocato fino all’altro ieri. Ma forse questo approccio si adatta alla struttura vittoriana della Roundhouse, che, in origine, era un capannone adibito alla riparazione di motori a vapore.
In realtà Byrne sfrutta, con grande spiegamento di mezzi, idee che girano come minimo dagli anni ’70 (se non prima) e hanno raggiunto una certa notorietà all’epoca delle performance Fluxus (far suonare gli oggetti). Cioè, in questo caso quello che fa non è farina del suo sacco. Però almeno, grazie alla sua notorietà, ha il merito di proporre le suddette idee a un pubblico che altrimenti non le avrebbe mai conosciute…

Ed ecco anche un nuovo video
A beautiful sonic boom
In particular conditions the sound waves can become visible. This Atlas V launched from Kennedy Space Center at Feb. 11 2010, fly through a sun dog.
A sun dog is a prismatic bright spot in the sky caused by sun shining through ice crystals. The Atlas V rocket exceeded the speed of sound in this layer of ice crystals, making the shock wave visible from the ground (from 1’56”).
Fibers that hear and sing
After the fibers made by cassette tape played by moving a tape head over the fabric, here it is fibers that can hear and sing by themselves.
To Yoel Fink, an associate professor of materials science and principal investigator at MIT’s Research Lab of Electronics, the threads used in textiles and even optical fibers are much too passive. For the past decade, his lab has been working to develop fibers with ever more sophisticated properties, to enable fabrics that can interact with their environment.
In the August issue of Nature Materials, Fink and his collaborators announce a new milestone on the path to functional fibers: fibers that can detect and produce sound. Applications could include clothes that are themselves sensitive microphones, for capturing speech or monitoring bodily functions, and tiny filaments that could measure blood flow in capillaries or pressure in the brain.
Despite the delicate balance required by the manufacturing process, the researchers were able to build functioning fibers in the lab. “You can actually hear them, these fibers,” says Chocat, a graduate student in the materials science department. “If you connected them to a power supply and applied a sinusoidal current” — an alternating current whose period is very regular — “then it would vibrate. And if you make it vibrate at audible frequencies and put it close to your ear, you could actually hear different notes or sounds coming out of it.”
In addition to wearable microphones and biological sensors, applications of the fibers could include loose nets that monitor the flow of water in the ocean and large-area sonar imaging systems with much higher resolutions: A fabric woven from acoustic fibers would provide the equivalent of millions of tiny acoustic sensors.
Read more details here.
Denoising Field Recordings
Interesting idea by Richard Reigner
Denoising Field Recordings documents an early attempt at using denoising-techniques in a creative and compositional manner. Instead of utilising noise-reduction-algorithms for their intended purpose (the restoration of damaged audio signals), these processes are applied to various field recordings of trains, streets, swimminghalls and public transport. Due to the fact that these recordings consist entirely of noises this operation transforms the originals into an uncanny hybrid of newly introduced processing artefacts, occasional silence and sporadically audible traces of the original field recordings. What kind of sound-aesthetics can emerge while denoising field recordings? Which audible parameters are able to resist this audio-erasement-process? How are these traces comparable to the visual remanences of Robert Rauschenberg’s erasure of a De Kooning drawing?
Denoising Field Recordings is released as a limited edition of see-through 12″ vinyl with an intruiging white-on-white cover designed by Hans Renzler. The digital version is available exlusively at Zero” (not free – must register to download).
Click here or here to listen to some results of applying noise reduction algorithms to noise.
Free Sound Samples
A great bunch of free sound samples from Open Path Music, The Berklee College of Music and the Worldwide Community of Csound Developers.
Some links are broken, but the majority are working.
Get the index here.
Piano Migrations Installation
Installation by Kathy Hinde
The inside of an old upright piano, rescued from destruction, is transformed into a kinetic sound sculpture. Video projections move across the surface of the piano strings, triggering small machines to twitch and flutter causing the strings to resonate. The video is visually akin to a musical score or piano roll, and this installation can also become the site for a live performance.
The video is analysed by a MaxMSP patch which divides the screen into a 5×5 grid to correspond to the motors and solenoids which are also arranged in a 5×5 grid on the piano. Movement or any change sensed in the video triggers a device in the corresponding square of the grid – the result is that the fluttering and movement of a bird triggers a device closest to it on the piano.
MaxMSP programming by Matthew Olden
Commissioned by Lumin, May 2010
Sun Boxes

Sun Boxes is a sound installation created by Craig Colorusso.
It’s comprised of twenty speakers operating independently each powered by solar panels. There is a different guitar sample in each box all playing together making the composition. The guitar samples are all of different lengths so the whole piece keeps evolving.
Participants are encouraged to walk amongst the speakers. It sounds different inside of the array. There is a different sense of space inside. Certain speakers will be closer and louder therefore the piece will sound different to different people in different positions throughout the array. Creating a unique experience for everyone.
There are no batteries involved. The Sun Boxes are reliant on the sun. When the sun sets the music stops. The piece changes as the length of the day changes making the participants aware of the cycle of the day.
It’s a very interesting idea. I would like to know how powerful each speaker is. 5 Watt? 10?
Devuvuzelator
If you find hard to tolerate the vuvuzelas constantly playing below the World Cup’s matches, there is a solution.
According to isophonic.net, this instrument plays a note about 230-235 Hertz (roughly the B-flat below middle C). So we can apply a notch filter on the fundamental frequency and the first harmonic (460-470) to greatly reduce the buzz. Listen to the before and after audio to confirm that it has indeed worked: you can still hear the horns, because the higher partials are intact, but they aren’t so loud. (Note that the effect takes a couple of seconds to work, at the start of the “after” sample.)
People at isophonic.net has created a VST plugin for windows and a LADSPA plugin for Mac OS/X that makes the job. Download from isophonic.net page.
The LADSPA plugin should work on Linux also, but we can do the same work using jack-rack. Here there are instructions that works on any linux box with jack and jack-rack.
But the real solution is to love the vuvuzelas. As John Cage argues:
If something is boring after two minutes, try it for four. If still boring, then eight. Then sixteen. Then thirty-two. Eventually one discovers that it is not boring at all.
The sound of a “God particle”

ATLAS is a particle physics experiment at the Large Hadron Collider at CERN. Starting in late 2009/2010, the ATLAS detector will search for new discoveries in the head-on collisions of protons of extraordinarily high energy. ATLAS will learn about the basic forces that have shaped our Universe since the beginning of time and that will determine its fate. Among the possible unknowns are the origin of mass, extra dimensions of space, unification of fundamental forces, and evidence for dark matter candidates in the Universe.
ATLAS is known because of the research for the Higg’s Boson, the so called “God particle”. Now this research generates sounds. Lily Asquith is a particle physicist who has just finished her PhD at University College London. Her work on this project has been to identify physics processes for sonification and to convert real and simulated ATLAS data into files readable by audio software. Lily came up with this idea whilst trying to describe to a very patient friend what she thought different particles would sound like.
Now a group of particle physicists, composers, software developers and artist is working on sonification of ATLAS data. The data are first processed using the vast and all-powerful ATLAS software framework. This allows raw data (streams of ones and zeroes) to be converted step-by-step into ‘objects’ such as silicon detector hits and energy deposits. We can reconstruct particles using these objects. The next step is to convert the information into a file containing two or three columns of numbers known as a “breakpoint file”. It can also be used as a “note list”. This kind of file can be read by compositional software such as the Composers Desktop Project (CDP) and Csound software used for this project.
An excerpt.
- The decay of a God particle
This example maps properties of the Higgs jet to properties of sound. A jet is made up of lots of cells containing energy deposits. Each cell has an energy, a distance and an angular distance (dR) associated with it. So each cell can be heard as a separate note in this example. This is quite a long track (about 90 seconds). The sounds reduce in density very much towards the end, with isolated events separated by silences of several seconds.
Tesla Coil Music
The sound is really produced by the coils. To play an A at 440 Hz the coil generate 440 lightnings per second. The temperature of the lightning is so high that compress the air around generating an audio wave.
Space Audio
A good site of “sounds of space” collected by U Iowa instruments on various spacecraft.
Here you can find many sounds “recorded” (remember that this are radio frequencies not audio frequencies) by Cassini, Voyagers and Galileo spacecrafts during the Jupiter and Saturn missions.
The site is Space Audio.
Here you can listen to the famous Cassini’s sound recorded near Saturn claimed to resemble to an alien voice if transposed one octave up preserving the duration:
Silophone
Silophone combines sound, architecture, and communication technologies to transform a significant landmark in the industrial cityscape of Montreal, Canada.
By telephone, or even the internet, they will send the sound of your choice echoing through the incredible acoustics of abandoned rusted halls and corridors of this imposing building.
Silo #5 is an abandoned grain storage facility in the port of Montréal. A quarter of a mile long and over twenty storeys high, it has a total capacity of five million bushels, or enough wheat to make 230 million loaves of bread. The building was constructed in several stages between 1903 and 1958. The newest part of the building was designed to last for generations, however due to changes in the global grain market and to the general trend of de-industrialization in North America at the end of the 20th century, the building became redundant less than forty years after its completion. Since 1994, Silo #5 has stood empty, and its fate has been hotly debated. The building is situated in one of Montréal’s oldest industrial districts, now rapidly being gentrified and renovated for high-tech commercial, luxury residential, and tourism/leisure industry uses.
The portion of the structure used by Silophone is constructed entirely of reinforced concrete, measures 200 metres long, 16 metres wide and approximately 45 metres at its highest point. The main section of the building is formed of approximately 115 vertical chambers, all 30 metres high and up to 8 metres in diameter. These tall parallel cylinders, whose form evokes the structure of an enormous organ, have exceptional acoustic properties: most notably, a stunning reverberation time of over 20 seconds. Anything played inside the Silo is euphonized, made beautiful, by the acoustics of the structure. All those who have entered have found it an overwhelming and unforgettable experience.
telephone access
Using your telephone, you can enter into — and participate in — the acoustic world of the Silo. More than one person can use the telephone system at once, so when you telephone you may find somebody else already in the Silo. This teleconference system was specifically adapted for use in the Silophone by engineers from Bell’s Emerging Technologies Group.
To call the Silophone from North America: 1.514.844.5555
From the rest of the world: 001.514.844.5555
Wait until the second ring, then start talking.
audio website
Go to the play page of this website to access the on-line dimension of the Silophone musical instrument. From this page, you can send pre-recorded sound files into Silophone by browsing through the thousands of uploaded sounds, or by uploading your own soundfile.
Whenever anyone is playing the Silophone over the telephone, the web, or the sonic observatory, you can hear the results by tuning into our live RealAudio stream. To hear the Silophone stream now, click the “hear Silophone” link at the bottom left hand corner of the page.
 |
 |
 |
 |
Bloop
The Bloop is the name given to an ultra-low frequency and extremely powerful underwater sound detected by the US National Oceanic and Atmospheric Administration (NOAA) several times during the summer of 1997. The source of the sound remains unknown.
According to thw NOAA description
it rises rapidly in frequency over about one minute and was of sufficient amplitude to be heard on multiple sensors, at a range of over 5,000 km.
5000 km is a grrreeeat distance for a sound, event in the water that conduct the sounds better than air. While the audio profile of the bloop does resemble that of a living creature, the system identified it as unknown because it was far too loud for that to have been the case: it was several times louder than the loudest known biological sound.
The bloop sound it’s too low to be perceived by a human ear. If transposed up by a factor of 8 (3 octaves), it sounds like this. and here by a 16 factor (4 octaves).
It was eventually identified as an ice quake.
The Power of the Slinkies
 For italian people:
For italian people:
Slinky è il nome commerciale di questo giocattolo, formato da una lunga molla elicoidale, in voga (boh) forse 20-30 anni fa (è stato inventato negli anni ’40; io ne ho almeno 4/5, ma non ricordo quando le ho comprate).
Vedi anche wikipedia.
A sound wave in a long wire travels back and forth and produces an echo effect. This fact was well known to the old sound engineers and the so called spring reverberator was largely used in the analogical era.
In this video micolich shows the power of long springs. When touched, the sound travels repeatedly along the whole length of the spring producing a stream of little echoes with decreasing amplitude. But the sound speed is high, so the time distance between echoes is a question of milliseconds. As result we can’t perceive the single echo, but a decreasing halo that extend the sound: this is the reverberation.
Electromagnetic sounds from planets
Another fascinating recording of space sounds captured by a NASA spacecraft.
This time it’s Jupiter sounds (electromagnetic “voices”) recorded by the Voyager. The complex interactions of charged electromagnetic particles from the solar wind , planetary magnetosphere etc. create vibration “soundscapes”.
Jupiter is mostly composed of hydrogen and helium. The entire planet is made of gas, with no solid surface under the atmosphere. The pressures and temperatures deep in Jupiter are so high that gases form a gradual transition into liquids which are gradually compressed into a metallic “plasma” in which the molecules have been stripped of their outer electrons. The winds of Jupiter are a thousand metres per second relative to the rotating interior. Jupiter’s magnetic field is four thousand times stronger than Earth’s, and is tipped by 11° degrees of axis spin. This causes the magnetic field to wobble, which has a profound effect on trapped electronically charged particles. This plasma of charged particles is accelerated beyond the magnetosphere of Jupiter to speeds of tens of thousands of kilometres per second. It is these magnetic particle vibrations which generate some of the sound you hear on this recording.
It’s interesting to compare this recording with some analog electronic music from the sixties (cfr. Screen (1968) by Jaap Vink) or some orchestral compositions by Gyorgy Ligeti (Lontano (1967) or Atmosphère).
In addition should be interesting to know if and how this recordings had been edited by the people of Brain/Mind Research that sell many NASA recordings.
Here are similar recordings from Uranus…
… and Neptune.
Animals sound perception: elephants
An interesting table showing the hearing ranges for some animals [from Animal Behavior Online]
| domestic cats | 100-32000 Hz |
| domestic dogs | 40-46000 Hz |
| African elephants | 16-12000 Hz |
| bats | 1000-150000 Hz |
| rodents | 70-150000 Hz |
I am impressed by the incredible hearing range of the rodents.
The infrasonic communications of the elephants is well known. African elephants have a social structure best described as fluid; animals move freely over wide areas, sometimes affiliating with other animals. Female members of a family tend to stay together, and of course their juveniles travel with them. These female-centered groups may merge with other such groups periodically. Adult males are less likely to join groups.
Female African elephants use “contact calls” to communicate with other elephants in their bands (usually a family group). These infrasonic calls, with a frequency of about 21 Hz and a normal duration of 4-5 seconds, carry for long distances (several kilometers), and help elephants to determine the location of other individuals. Calls vary among individual elephants, so that others respond differently to familiar calls than to unfamiliar calls. Perhaps elephants can recognize the identity of the caller.
Perception of infrasounds, however, presents some specific problems. An object smaller than the distance between waves is a poor receiver for those waves. Thus infrasonic receivers need to be large. This is probably the reason that infrasonic communication is used by only a few animals, and the best understood infrasonic communication system is the African elephant’s.
The large pinnae (external portion of the ear; trad.: il padiglione auricolare) in the African elephant may play an important role in the elephant’s perception of low frequency sounds, which are significant in communication among elephants. Receiving structures whose size is matched to the wavelength of the sound perform better.
Save Our Sounds
In a radio programme called Save Our Sounds, the BBC asked their listeners to upload sound recordings from where they live in order to create an audio map of the world.
Here is the call:
Help to create a snapshot of the world in sound!
We’re really excited about Save Our Sounds, but we need your help to create an audio map of the world. We’re especially keen to preserve endangered sounds for future generations.
You can get involved by sending us sounds from where you live, and then listen your way around the world with our interactive map.
Please upload your sounds onto our map.
Find out more about Save Our Sounds and follow our recording tips in order to collect the best quality sound.
So get recording and take us all on a journey through sound!
In this page you can listen to audio fragments from the whole world.

Music for cats
 This site claims to produce “authentic cat music based on feline communication and hearing.”
This site claims to produce “authentic cat music based on feline communication and hearing.”
When I was a student, there was cats on my house. I remember that, when listening to music, sometimes I observed their behavior and try to imagine their perception of the sounds and the meaning of the music for them.
I also remember that sometimes they moved a paw in front of the speaker. Not on the speaker, but in front of it, about half meter distant (speakers was on the floor), like trying to touch something.
Now I have no cats, so I can’t test it. But if someone could try and refer, it should be interesting. The songs are written in three different styles – each song style is designed to convey and evoke a particular mood.
Listen to samples from the main page.
The DFW Audio Project
 …it’s a series of audio recordings by David Foster Wallace, the author of Infinite Jest, which Time included in its All-Time 100 Greatest Novels list.
…it’s a series of audio recordings by David Foster Wallace, the author of Infinite Jest, which Time included in its All-Time 100 Greatest Novels list.
The collection is here and is broken into four categories:
Ice sounds
Besides the ocean audio stream, the Alfred Wegener Institute has many recordings of underwater acoustic phenomena and ice sounds that you can listen from this page.
Among this materials, there are some sounds caused by the icebergs whose origin is not yet known. Click the image.

PALAOA
The hydrophones of German Alfred-Wegener-Institut transmitting live from the Ocean below the Antarctic Ice in the Atka Bay. This project is called PALAOA (PerenniAL Acoustic Observatory in the Antarctic Ocean) that means “whale” in Hawaiian.
Click here for mp3 audio stream.
Please note, this transmission is not optimized for easy listening, but for scientific research. It is highly compressed (24kBit Ogg-Vorbis), so sound quality is far from perfect. Additionally, animal voices may be very faint. Amplifier settings are a compromise between picking up distant animals and not overdriving the system by nearby calving icebergs. So you might need to pump up the volume – but beware of sudden extreamely loud events.
There is also a webcam showing images like this one (click to enlarge)

Gelie
An interesting application for iPhone that links sound and gestures. The sound needs some improvements but the idea is stimulating.
Playing the building
Playing the Building is a sonic project by ex-Talking Head David Byrne that came to London in 2009. You could sit down at an “antique organ” and hit whatever keys or chords your heart desired—but you wouldn’t be producing notes.
You would instead trigger a “series of devices,” as Byrne describes them: hammers and dampers distributed throughout the building in which you sat. Distant windowpanes and metal cross-beams, hooked up to wires, would begin to vibrate, tap, and gong. Imagine someone like this sitting in the darkness beneath Manhattan, causing haunted musics and unexplained knocks inside rooms and abandoned buildings around the city. Now, even urban infrastructure will be musicalized.
LRAD
The LRAD (Long Range Acoustic Device) can emit a tone higher than the normal human threshold of pain. It was used for the first time in the USA in Pittsburgh during the time of G20 summit on September 24-25th, 2009.
https://youtu.be/QSMyY3_dmrM
By the way, a good book about it: Sonic Warfare – Sound, Affect, and the Ecology of Fear by Steve Goodman (MIT Press, see also this review on Rhizome).
Bio Circuit – a wearable soundscape
This video depicts the collaborative wearable technology project of Bio Circuit in action. Bio Circuit was created at Emily Carr University by Industrial Design student Dana Ramler, and MAA student Holly Schmidt.
Bio Circuit is a vest that provides a form of bio feedback using data from the wearer’s heart rate to determine what “sounds” they hear through the speaker embedded in the collar of the garment. The wearer places the heart rate monitor around the ribcage, resting against the skin and close to the heart. An MP3 audio player embedded in the vest plays the audio track related to that specific heart rate. The audio tracks are soundscapes mixed from a range of ambient sounds. If the wearer’s heart rate is low, the soundscape will reflect a quiet natural area with sounds such as water, birds and insects. If the wearer has a high heart rate then they will hear a cacophony of urban sounds such as people talking and traffic.
Bio Circuit stems from our concern for ethical design and the creation of media-based interactions that reveal human interdependence with the environment. With each beat of the heart, Bio Circuit connects the wearer with the inner workings of their body. In this sense the garment functions like other biofeedback devices that use sensors to provide a person with information about their physiological state. With Bio Circuit, we are proposing that these kinds of devices could extend a person’s awareness to include the environment.
visit danaramler.com for more information
From Vimeo
Old School Computer Music
 Dr. Boulanger has put up a wondeful collection of Csound mp3s at Csounds.com.
Dr. Boulanger has put up a wondeful collection of Csound mp3s at Csounds.com.
Download 4csoundCompositions.zip (99.1 MB)
The pack comes with 20 tracks, with everything from ambient to minimal to cheesy techno to synth-generated halloween sound fx. All of the original source code is included in case you are curious to see what these compositions look like in their original state.
From The Csound Blog
Excerpts:
- Blue Cube by Kim Cascone
- Cave Water Spirits by Man Kei Lee
- Descent by ??
- Nuclear Energy by Jacob Joaquin (old style analog synth with Csound)
Alien Safe???
Last week the Conservatorium (the public school of music here in Italy) where I work in Trento, bought a new mixer for the electronic music studio. It’s a Mackie 1640i with ADC/DAC included, so you can connect 16 in and 16 out to your computer through a single firewire cable (no more wires, wow!).
Looking at the box, I saw the usual set of icons (this side up, fragile, keep dry, etc), but there was one more. A single icon featuring the Jarod face and saying ALIEN SAFE.
ALIEN SAFE???
Here it is. Click the images to enlarge.
 |
 |
Muxicall
At a first sight Muxicall seems to be another piano on the net like many others. But there is an important and interesting difference: all the people connected play together and everyone can hear all the notes.
All the users connected share the same instrument and a sort of collective improvisation can arouse. Interesting concept, but the reaction time can be a problem: the users can experience a sensible latency due to flash and the network itself.
Muxicall was created by Diana Antunes as part of her work for the New Technologies of Communication degree at the University of Aveiro (Portugal).

inudge
A better ToneMatrix with a drum, more instruments and melodic lines to play with. Have fun here.

140 chars of music
A twitter. An SMS. That’s the challenge. Writing a piece of electronic digital music using only 140 chars of code.
It started as a curious project, when live coding enthusiast and Toplap member Dan Stowell started tweeting tiny snippets of musical code using SuperCollider. Pleasantly surprised by the reaction, and “not wanting this stuff to vanish into the ether” he has recently collated the best pieces into a special download for The Wire.
Of course, to satisfy such a constraint, you need a very compact programming language and SuperCollider is the best choice (see also here). It is an environment and programming language for real time audio synthesis and algorithmic composition. It provides an interpreted object-oriented language which functions as a network client to a state of the art, realtime sound synthesis server.
SuperCollider was written by James McCartney over a period of many years, and is now an open source (GPL) project maintained and developed by various people. It is used by musicians, scientists and artists working with sound. For some background, see SuperCollider described by Wikipedia.
You can download the code snippets here. Note that many of these pieces are actually generative, so if you have a working SuperCollider environment and re-run the source code you get a new (i.e. slightly different) piece of music.
Some excerpts:
The artists notes are here.
Speaking of Music: Pierre Boulez
February 16, 1986.
Charles Amirkhanian interviews Pierre Boulez and Andrew Gerzso as part of the Speaking of Music series. Boulez discusses the pros and cons of microtonal music, spatial music, as well as delving into the technical details of his latest work, “Répons”.
Symphonies of the Planets 1
 In the August and September 1977, two Voyager spacecraft were launched to fly by and explore the great gaseous planets of Jupiter and Saturn.
In the August and September 1977, two Voyager spacecraft were launched to fly by and explore the great gaseous planets of Jupiter and Saturn.
Voyager I, after successful encounters with the two, was sent out of the plane of the ecliptic to investigate interstellar space.
Voyager II’s charter later came to include not only encounters with Jupiter (1979) and Saturn (1981), but also appointments with Uranus (1986) and Neptune (1989).
The Voyagers are controlled and their data returned through the Deep Space Network, a global spacecraft tracking and communications system operated by the JPL for NASA.
Although space is a virtual vacuum, this does not mean there is no sound in space. Sound does exist as electronic vibrations. The especially designed instruments on board of the Voyagers performed special experiments to pick up and record these vibrations, all within the range of human hearing.
These recordings come from a variety of different sound environments, e.g. the interaction of the solar wind with the planet’s magnetosphere; electromagnetic field noise; radio waves bouncing between the planet and the inner surface of the atmosphere, etc.
In 1993 NASA published excerpts from these recordings in a set of 5 CD (30 minutes each) called Symphonies of the Planets (now out of print).
This is the CD 1.
- Voyager recordings – Symphonies of the Planets 1
ToneMatrix
 Andate a sperimentare questo giochino, tanto semplice quanto ipnotico.
Andate a sperimentare questo giochino, tanto semplice quanto ipnotico.
Si tratta di un semplice sintetizzatore di onde sinusoidali pilotato da un sequencer a 16 passi in forma di matrice.
Cliccate la matrice per inserire una nota, ricliccate per cancellarla. La posizione basso-alto corrisponde all’altezza. Purtroppo non è possibile controllare la dinamica e nemmeno il metronomo, così come non si può cambiare la scale su cui sono distribuite le altezze. Ciò nonostante è difficile smettere.
Il tutto è basato su AudioTool, un insieme di strumenti, realizzati in Flash, per generare musica su internet.
Programmato da André Michelle.
Segnalato da Vinz.
Frequenze di taglio degli MP3
La qualità di un MP3 dipende in gran parte dal codificatore. Le specifiche, infatti, dicono cosa fare, ma non come farlo (a differenza della decodifica, che invece è un processo puramente meccanico). Proprio per questo, un codificatore di bassa qualità è riconoscibile ascoltando persino un brano a 320 kbit/s. Ne consegue che non ha senso parlare di qualità di ascolto di un brano di 128 kbit/s o 192 kbit/s senza un riferimento al codec utilizzato. Una buona codifica MP3 a 128 kbit/s prodotta da un buon codificatore produce un suono migliore di un file MP3 a 192 kbit/s codificato con uno scarso codificatore.
I test, come quello del post precedente, sono eseguiti con L.A.M.E. (Lame Ain’t MP3 Encoder) che è riconosciuto come uno dei migliori (forse il migliore per compressione da 128 in su).
Proprio LAME ci dà le frequenze di taglio ai vari livelli di compressione. Nel processo di codifica, viene attivata una serie di filtri per la suddivisione del segnale in bande che si ferma a una altezza diversa per ciascun bitrate. La porzione di segnale che eccede l’ultima banda viene eliminata con un filtro passabasso che inizia la sua attenuazione a una certa frequenza (inizio in tabella) e taglia completamente oltre un certo livello (fine in tabella).
È possibile anche disattivare il suddetto filtro (c’è una opzione in LAME), tuttavia facendolo si rischiano artefatti identificabili, di solito, come un certo tipo di effetto che assomiglia un po’ ad un flanger (si sente spesso nell’audio dei film rippati e troppo compressi).
Ecco la tabella:
| kbps | area di taglio: inizio, fine |
| 128 | 16538 Hz – 17071 Hz |
| 160 | 17249 Hz – 17782 Hz |
| 192 | 18671 Hz – 19205 Hz |
| 224 | 19383 Hz – 19916 Hz |
| 256 | 19383 Hz – 19916 Hz |
| 320 | 20094 Hz – 20627 Hz |
La tabella si legge così: per es. nel caso di 128 kbps, l’attenuazione delle frequenze inizia a 16538 Hz e aumenta fino a 17071 Hz, oltre i quali tutto viene eliminato. Quindi, in astratto, anche l’MP3 a 320 è sensibilmente inferiore alla qualità CD. Naturalmente qualcuno potrebbe dire che le frequenze oltre i 20 KHz difficilmente si sentono per una combinazione di qualità dell’impianto audio e orecchie dell’ascoltatore.
In realtà, come ha fatto osservare Angelo nel commento al post precedente, è un problema di educazione all’ascolto:
A test given to new students by Stanford University Music Professor Jonathan Berger showed that student preference for MP3 quality music has risen each year. Berger said the students seem to prefer the ‘sizzle’ sounds that MP3s bring to music.[27]
Others have reached the same conclusion, and some record producers have begun to mix music specifically to be heard on iPods and mobile phones.[28]
However, the study was criticized for being a short-term A/B test, which does not reflect the listeners preferences when they listen to music for prolonged periods.[29]
[wikipedia]
[27][28][29] sono riferimenti bibliografici citati in wikipedia. Cliccate i numeri per andare agli articoli. Il primo è l’articolo di Berger, gli altri sono commenti. Credo che dovremmo iniziare una seria riflessione sui cambiamenti delle modalità di ascolto sia della musica che dei suoni naturali.
Differenza fra originale e MP3 128 kbps
Quello che vedete qui sotto è lo spettro di un brano dei Portished: Nylon Smile. Musica non classica e non acustica.
Sopra, i due canali del brano non compresso. Sotto, dopo la riga grigia e la scritta “unite – sync”, quelli dello stesso pezzo compresso in MP3 128 kbps. Lo spettro è volutamente in bianco/nero per evidenziare le differenze.
Se osservate attentamente noterete che, nello spettro superiore (non compresso), la posizione delle linea rossa che ho messo per segnare la frequenza più alta è oltre i 20000 Hz, mentre in quello inferiore si ferma prima, a circa 17000 Hz. Ecco, questa è la banda, visibile a una prima occhiata, che si perde con questo livello di compressione. Poi bisognerebbe entrare nei particolari per vedere se qualcosa manca anche sotto.

Ne consegue che il distribuire musica di qualsiasi tipo in formato MP3 a 128 kbps, come fa la maggior parte dei rivenditori via internet di musica genericamente pop, equivale a un furto di banda di circa 3 KHz e diffonde una abitudine a una banda più ristretta.
Adesso mi direte che, tanto, la banda ristretta la diffondono già le maledette cuffiette, però….
La fine del CD (ma anche degli MP3 < 256)
…almeno a casa mia.
Dunque, stanco di avere la musica dispersa fra alcune migliaia di CD, altrettanti vinili e molti file su computer (tutti rigorosamente acquistati, CC o digitalizzati da dischi che possiedo), ho deciso di digitalizzare il tutto, metterlo su un HD in rete e utilizzare un vecchio portatile come jukebox (ovviamente con linux).
Un gran lavoro che, per ora, ho fatto solo su un quarto circa dell’insieme, il che spiega anche la non assidua continuità dei post di settembre.
Il sistema, alla fine, è composto da un sistema RAID da 2 terabytes (di cui si usa solo una piccola parte) letti da un portatile di vecchia generazione (avrà 5 anni, monoprocessore da 2.8 GHz) su cui gira un Ubuntu Jaunty con scheda M-Audio, collegata a un micro mixer che va a due casse auto-amplificate Event ALP 5 oppure Yamaha HS80M.
Come software uso Rhythmbox (sto provando anche Banshee). Il software si fa un database di tutto ciò che è audio e lo indicizza in base ai tag. Poi si possono selezionare i brani in base a autore, titolo e/o genere. Inoltre il computer è in rete, quindi si può ascoltare qualunque cosa si trovi su internet, comprese radio, netlabel, podcast etc.
Bene, considerando che la mia discoteca è alquanto eterogenea e va da Luigi Nono fino ai Sex Pistol, sono stato colpito dalla bassa qualità degli MP3. Con casse di questo tipo, che comunque sono lontane dal top, gli MP3 a 128 kbps risultano fastidiosamente ed evidentemente privi delle frequenze alte, non solo con la musica classica, ma anche ascoltando i Rolling Stones. Perfino a 192, la differenza con l’originale si sente e per avere qualcosa di accettabile bisogna arrivare almeno a 256 kbps.
Per quel che riguarda la musica classica, lo sapevo già, ma quello che mi ha colpito è che il degrado è sensibile anche con musica il cui punto di forza non è certamente la pulizia e la chiarezza del suono (tipo Rolling Stones, appunto). Notate che, al di là delle buone casse, non ho una stanza particolarmente insonorizzata o similia. È una stanza normale.
In effetti, all’inizio pensavo di convertire in FLAC (compressione senza perdita) gli album più raffinati e usare MP3 intorno ai 192 kbps, o meno, per il resto. Invece un po’ di prove mi hanno convinto (direi quasi costretto) a usare MP3 solo a 320 oppure con bitrate variabile alla massima qualità per i gruppi un po’ “rumorosi” e andare in FLAC per tutto il resto.
L’effetto collaterale è che non compro più musica in MP3 inferiore a 256 kbps e solo se il prezzo è basso. Altrimenti mi devono dare un file compresso ma senza perdita (FLAC, APE, LA).
La massificazione dell’MP3 si traduce in una perdita della qualità appena conquistata con il passaggio al CD. Magari lo sapevamo già, ma vederlo e sentirlo è un’altra cosa.
Sounds from Saturn
Saturn is a source of intense radio emissions, which have been monitored by the Cassini spacecraft. The radio waves are closely related to the auroras near the poles of the planet. These auroras are similar to Earth’s northern and southern lights. This is an audio file of radio emissions from Saturn.
The Cassini spacecraft began detecting these radio emissions in April 2002, when Cassini was 374 million kilometers (234 million miles) from the planet, using the Cassini radio and plasma wave science instrument. The radio and plasma wave instrument has now provided the first high resolution observations of these emissions, showing an amazing array of variations in frequency and time. The complex radio spectrum with rising and falling tones, is very similar to Earth’s auroral radio emissions. These structures indicate that there are numerous small radio sources moving along magnetic field lines threading the auroral region.
Time on this recording has been compressed, so that 73 seconds corresponds to 27 minutes. Since the frequencies of these emissions are well above the audio frequency range, we have shifted them downward by a factor of 44.
The Cassini-Huygens mission is a cooperative project of NASA, the European Space Agency and the Italian Space Agency. The Jet Propulsion Laboratory, a division of the California Institute of Technology in Pasadena, manages the mission for NASA’s Science Mission Directorate, Washington, D.C. The Cassini orbiter was designed, developed and assembled at JPL. The radio and plasma wave science team is based at the University of Iowa, Iowa City.
For more information about the Cassini-Huygens mission, visit http://saturn.jpl.nasa.gov and the instrument team’s home page, http://www-pw.physics.uiowa.edu/cassini/.
Credit: NASA/JPL/University of Iowa

From NASA.gov
The Vancouver Soundscape
 The World Soundscape Project (WSP) was established as an educational and research group by R. Murray Schafer at Simon Fraser University during the late 1960s and early 1970s. It grew out of Schafer’s initial attempt to draw attention to the sonic environment through a course in noise pollution, as well as from his personal distaste for the more raucous aspects of Vancouver’s rapidly changing soundscape. This work resulted in two small educational booklets, The New Soundscape and The Book of Noise, plus a compendium of Canadian noise bylaws. However, the negative approach that noise pollution inevitably fosters suggested that a more positive approach had to be found, the first attempt being an extended essay by Schafer (in 1973) called ‘The Music of the Environment’, in which he describes examples of acoustic design, good and bad, drawing largely on examples from literature.
The World Soundscape Project (WSP) was established as an educational and research group by R. Murray Schafer at Simon Fraser University during the late 1960s and early 1970s. It grew out of Schafer’s initial attempt to draw attention to the sonic environment through a course in noise pollution, as well as from his personal distaste for the more raucous aspects of Vancouver’s rapidly changing soundscape. This work resulted in two small educational booklets, The New Soundscape and The Book of Noise, plus a compendium of Canadian noise bylaws. However, the negative approach that noise pollution inevitably fosters suggested that a more positive approach had to be found, the first attempt being an extended essay by Schafer (in 1973) called ‘The Music of the Environment’, in which he describes examples of acoustic design, good and bad, drawing largely on examples from literature.
Schafer’s call for the establishment of the WSP was answered by a group of highly motivated young composers and students, and, supported by The Donner Canadian Foundation, the group embarked first on a detailed study of the immediate locale, published as The Vancouver Soundscape, and in 1973, on a cross-Canada recording tour by Bruce Davis and Peter Huse, the recordings from which formed the basis of the CBC Ideas radio series Soundscapes of Canada. In 1975, Schafer led a larger group on a European tour that included lectures and workshops in several major cities, and a research project that made detailed investigations of the soundscape of five villages, one in each of Sweden, Germany, Italy, France and Scotland. The tour completed the WSP’s analogue tape library which includes more than 300 tapes recorded in Canada and Europe with a stereo Nagra. The work also produced two publications, a narrative account of the trip called European Sound Diary and a detailed soundscape analysis called Five Village Soundscapes. Schafer’s definitive soundscape text, The Tuning of the World published in 1977 [trad. it. “Il Paesaggio Sonoro”, Ricordi/Unicopli], and Barry Truax’s reference work for acoustic and soundscape terminology, the Handbook for Acoustic Ecology published in 1978, completed the publication phase of the original project.
Excerpts from The Vancouver Soundscape 1973:
The WSP group at SFU, 1973; left to right: R. M. Schafer, Bruce Davis, Peter Huse, Barry Truax, Howard Broomfield

Ocean & Cricket Music
 Walter De Maria (nato ad Albany, in California, nel 1935) è uno dei principali esponenti della corrente artistica detta Land Art alla quale è passato dopo un’iniziale esperienza di scultore nell’ambito della Minimal Art (alcune sue opere di questo periodo, come “Balldrop” del 1961, si trovano al Guggenheim Museum di New York).
Walter De Maria (nato ad Albany, in California, nel 1935) è uno dei principali esponenti della corrente artistica detta Land Art alla quale è passato dopo un’iniziale esperienza di scultore nell’ambito della Minimal Art (alcune sue opere di questo periodo, come “Balldrop” del 1961, si trovano al Guggenheim Museum di New York).
Tra gli anni ‘60 e ‘70 inizia a intervenire direttamente sul territorio con le sue monumentali earth sculptures: nel 1968, per esempio, disegna con la calce delle linee parallele all’interno del Mojave Desert, in California, mentre nel 1977, in occasione di documenta, la grande rassegna di arte contemporanea che si svolge a Kassel, in Germania, ogni cinque anni, fa penetrare nel terreno un’asta metallica per un chilometro.
La sua opera più famosa, però, rimane senza dubbio “The Lightning Field” (1977): in questa monumentale installazione posta in un angolo remoto del deserto del New Mexico De Maria cerca la complicità della natura per mettere in scena un evento sempre straordinario. Dopo aver conficcato in verticale nel terreno 400 pali metallici appuntiti su un’area di circa 3 chilometri quadrati, ne sfrutta l’effetto-parafulmine durante i temporali raccogliendo e moltiplicando la potenza dei fulmini a servizio di un grandioso spettacolo di luce (nell’immagine).
[da Wikipedia]
Non tutti sanno, però, che De Maria ha anche firmato alcune opere sonore in cui lui stesso suona la batteria e la mixa con field recording, ora disponibili su UbuWeb.
Sounds of Everglades
 Sempre nel campo del field recording, ecco Sounds of the Everglades, una cassetta di circa 30 minuti registrata nelle paludi della Florida. Nel 1990 era in vendita a $3.99.
Sempre nel campo del field recording, ecco Sounds of the Everglades, una cassetta di circa 30 minuti registrata nelle paludi della Florida. Nel 1990 era in vendita a $3.99.
Tropical Rain Forest
Il titolo dice tutto. Quello che vi propongo oggi è un esempio di field recording che risale al 1986.
Si tratta di una registrazione di 22 minuti, effettuata in una foresta tropicale (dai suoni si direbbe localizzata in America del Sud, prob. Brasile), distribuita negli anni ’80 su cassetta da Moods Gateway Recording. Nessun trattamento, né montaggio sembra essere stato fatto. La qualità è quella dei registratori portatili a nastro dell’epoca, comunque buona, qui digitalizzata e convertita in mp3 a 128 kbps.
La varietà dei suoni e delle loro combinazioni è fantastica. La potete ascoltare in streaming o scaricare in mp3 (att.ne: è circa 21 Mb).
NB: attualmente esistono vari cd con questo titolo disponibili via internet. La registrazione non è questa. Questa non è più in distribuzione. Spesso quelle attuali sono registrazioni di sottofondo con musichetta applicata sopra, oppure sono divise in brani (uccelli, animali vari, indigeni, etc). Qui, invece, c’è la registrazione della foresta, pura e semplice, con la pioggia che va e viene, per 22 minuti.
MoPhO
La Mobile Phone Orchestra (MoPhO), creata presso il CCRMA dell’Università di Stanford, utilizza i cellulari come piattaforma musicale.
I particolari in questo articolo e nel video seguente.
Gioielli da onde audio
Il Sound Advice Project trasforma un’onda sonora in un bracciale. Lo fa online e ve lo vende.

In realtà il Sound Advice Project non è l’unico a lavorare su questo tema. Anche l’artista giapponese Sakurako Shimizu lo ha sviluppato. Grande idea quella dell'”I do” wedding band.
 |
 |
 |
Via Boing Boing
Facce elettriche
Daito Manabe trasforma i suoni in impulsi elettrici atti a stimolare i muscoli del viso e testa il sistema sui suoi amici.
Daito Manabe:Direction,programming and composition
supported by
Masaki Teruoka and Katsuhiko Harada: device
Taeji Sawai: sound design
upper left: Muryo Honma
upper right:Setsuya Kurotaki,
lower left: Motoi Ishibashi
lower right: Seiichi Saito
Theremin come controller
Pochi sanno che la Moog ha un canale su You Tube. E non molti sanno che Moog è anche uno dei più grandi produttori di Theremin. L’ultimo modello è l’Etherwave Plus.
Recentemente Moog ha esteso l’area di utilizzo dell’Etherwave Plus, impiegandolo come controller di una apparecchiatura analogica. In questo video lo si vede controllare il filtro di una Moog guitar con l’effetto di agire sul timbro di quest’ultima.
Dal punto di vista di un elettronico, il giochino è banale perché una tensione è una tensione, da qualsiasi parte venga e da qualsiasi cosa sia generata, tuttavia mostra chiaramente come il mondo dei controller audio potrebbe essere esteso in molti modi.
Moorer Interview
Gli amici di USO Project pubblicano una intervista in tre parti con James Andy Moorer, uno dei pionieri della computer music, che potete trovare sul loro blog.
Surround-O-Phonic Radio
 Che io sappia questa è la prima radio su internet e forse la prima radio in assoluto, che trasmette in 5+1. Se vi collegate vi arriva uno stream in formato wma (windows media audio) composto di front center, left, right, back left e right + subwoofer. Su linux lo sento, ma il mio impianto è al massimo quadrafonico.
Che io sappia questa è la prima radio su internet e forse la prima radio in assoluto, che trasmette in 5+1. Se vi collegate vi arriva uno stream in formato wma (windows media audio) composto di front center, left, right, back left e right + subwoofer. Su linux lo sento, ma il mio impianto è al massimo quadrafonico.
Ormai però l’uscita 5+1 c’è anche sulle schedine incluse nelle motherboard. Se qualcuno di voi ha un impianto adatto ci dica come va. Serve windows XP con windows media player e una connessione veloce perché il bitrate minimo è 128 kbps. Cliccate l’immagine.
Segnalato da Ermes.
Voice Box
 Cosa non si può fare con un po’ di FFT e di convoluzione?
Cosa non si può fare con un po’ di FFT e di convoluzione?
Quelli della Electro-Harmonix sono da sempre attenti alla tecnologia applicata al pop e sono anche abbastanza intelligenti. Così hanno fatto una simpatica scatolina, chiamata Voice Box, che incorpora un vocoder e una vocal harmony machine.
UPDATE 15/12
The Electro Harmonix Voice Box features 256-band vocoder, 3 multi-harmony modes: low & high (low, 3rd and 5th below, and high, 3rd and 5th above), octave (2 notes ) and whistle (creates a whistle playing an octave above the note you are playing), 9 user presets, professional pitch shift algorithm, gender mod (that builds man- or woman-like voice), natural glissando, reverb effect with separated controls for dry and effected vocals, built-in mic preamp, +48V phantom power, gain switch and balanced XLR line output to use it with almost any system.
This device is powered by the supplied DC power adapter and comes with die-cast chassis that makes it hard enough to use it on stage. The Electro Harmonix Voice Box Harmony Machine / Vocoder is now available and its recommended price is $215.
Ecco il demo.
FFT cat
Questa viene da un articolo di cui vi parlerò domani, ma anche da sola è troppo bella, anche se un po’ per addetti ai lavori…

Ipse Dixit
So che ridere (o piangere) sulle perle dei giornalisti è come sparare sulla Croce Rossa, ma ogni tanto non resisto.
Leggo su l’Unità online di oggi (NB: era il 22/09/2008)
Sono nati molti «negozi» on line che vendono registrazioni in formati digitali dai nomi improbabili come Aiff, Flac o Wav che sono la copia esatta, bit per bit, della registrazione originale.
[il neretto è mio, il pezzo è firmato Toni De Marchi]
Magari il giornalista sa esattamente di cosa parla e in effetti il resto dell’articolo non è male, ma frasi come questa danno l’impressione che non ne abbia proprio idea. Oppure è humour?
Lezione di Theremin
Ultimamente registro un aumento delle domande sul theremin, segno di un rinnovato interesse per questo strumento.
Beccatevi questa lezione di Thomas Grillo, in cui mostra chiaramente la tecnica sviluppata da Clara Rockmore per controllare l’intonazione e il vibrato, così vi fate un’idea.
E notate che lui ha un bel theremin, quello della Moog, non una cosa qualsiasi.
Suoni Atmosferici
Sferics sta per “atmospherics” ed è l’abbreviazione con cui si definiscono genericamente le radiofrequenze di origine atmosferica che viaggiano su frequenze di trasmissione molto basse (Very Low Frequency, da 3 kHz a 30 kHz). Sono state classificate in tre tipologie:
- Sferics propriamente detti: si tratta di segnali impulsivi generati dai lampi. Queste radiofrequenze viaggiano per migliaia di kilometri e assomigliano al suono della pancetta che frigge. Ecco un esempio.
- Tweeks: questi segnali sono sferics che viaggiano nella ionosfera, un medium dispersivo in cui le alte frequenze si muovono a maggiore velocità rispetto alle basse frequenze. Per questa ragione esibiscono un picco intorno ai 2000 Hz e assomigliano a degli uccellini.
- Whistlers: i più affascinanti. Si tratta di glissati discendenti, anche questi causati dalla dispersione atmosferica che fa sì che le alte frequenze arrivino prima delle basse. Ecco qui.
Tutti questi segnali sono stati registrati dall’INSPIRE VLF radio receiver presso il Marshall Space Flight Center della NASA a Huntsville, Alabama.
La cosa interessante è che è anche possibile ascoltare il ricevitore INSPIRE in diretta cliccando questo link. Ecco la pagina di riferimento. Non aspettatevi di sentire subito tweeks & whistlers, sono i più rari. Invece sentirete più facilmente suoni della prima categoria.
Un’altra cosa interessante è che tutti possono ricevere la banda VLF sul proprio PC, con questo semplice procedimento riportato da wikipedia (leggete PC-based VLF reception).
C’era una volta… (001)
… il Cracklebox (1975, nome orig. olandese Kraakdoos).
Questo geniale strumento, scaturito dalla mania di Michael Waiswisz di ficcare le dita nei circuiti delle radio a onde corte e alimentato soltanto da una batteria a 9V, utilizzava le proprietà di conduzione elettrica della pelle per connettere le varie parti di un circuito relativamente semplice, ma capace di emettere fischi, borbottii e vari lamenti.
Il corpo umano diventava così parte della circuiteria e la pelle agiva da cavo, potenziometro e condensatore.
Era prodotto dai laboratori STEIM di Amsterdam che, negli anni ’70 ne vendettero circa 4000 esemplari. La produzione era ricominciata alcuni anni fa, ma ora è nuovamente interrotta a causa della mancanza di alcuni componenti ormai obsoleti.
Il mio divertimento preferito, le rare volte che l’ho avuto in mano (prestito del mio amico e collega Roberto ‘Zoo’ Zorzi), era entrare in un grande magazzino con il cracklebox in tasca e accenderlo per qualche secondo guardandomi in giro, insieme a tutti i presenti, per cercare di capire da dove venivano quegli assurdi suoni. E i suoni erano questi:
Percezione delle altezze
Una ricerca di cui è stata data notizia su Nature #451 del 10 Gennaio (abstract qui; per l’intero testo è necessaria la registrazione) rivela che gli umani e i pipistrelli sono gli unici mammiferi a distinguere mediamente differenze di altezza così sottili (più di 10 per ottava; lo so che i musicisti ne sentono ben di più: qui si dice che anche un umanoide qualsiasi è in grado di distinguere un Do da un Re).
I gatti percepiscono solo differenze pari a circa una ottava (circa), i topi arrivano a 1/3 di ottava, i macachi arrivano al massimo a mezza ottava. In un comunicato stampa, uno degli autori, Itzhak Fried, afferma
It is indeed a mystery why such [frequency] in humans came to be. Why did we do this? Such selectivity is not needed for speech comprehension, but it may have a role in musical skill.
Che possa avere un ruolo nella abilità musicale mi sembra lapalissiano. La vera questione è perché abbiamo sviluppato questa capacità. Deriva forse dallo sviluppo del linguaggio oppure si è formata per qualche altra ragione e tutto ciò ha favorito lo sviluppo di un linguaggio complesso?
A chi è interessato a queste problematiche e legge bene l’inglese segnalo l’interessantissimo blog Babel’s Dawn.
Olio e Vetro
Queste registrazioni sono il risultato delle ricerche di Nikita Golyshev nel periodo che va da Marzo ad Agosto 2007.
L’obiettivo principale dell’esperimento era lo studio delle proprietà acustiche di sostanze come l’olio piazzate in diversi tipi di contenitori come bicchieri di cristallo e provette mediche.
Come tali, non hanno un diretto significato musicale, ma i suoni così ottenuti sono comunque interessanti, tali da essere pubblicati dalla netlabel Musica Excentrica.
L’intero corpus di 15 frammenti è pubblicato qui in formato MP3 oppure qui in FLAC. Intanto ve ne metto qui alcuni.
_________________________________
These records are the result of research made by Nikita Golyshev in a period between March and August of a year 2007. The main objective of this experiment was to detect some acoustic properties of oil as substance, placed in different capacities such as crystal glasses and medical bulbs.
The obtained 15 sound fragments are collected by the frequency and spectrum analysis of oil behaviour, its molecular changes in various environments (aggressive and non-agressive) and wide range of oil interactions with metal.
All fragments are here in MP3 format or here in FLAC.
Ornitologia e musica
Updated 20150604
Tanto per restare in campo ornitologico e ascoltare un po’ di di Messiaen, godetevi questa Grive-Musicienne tratta dai Petites esquisses d’oiseaux del 1985 per pianoforte solo (grive musicienne = Turdus philomelos, è il Tordo bottaccio; vive in tutta Europa, Asia, Africa del nord ai margini di boschi e foreste ed è chiamato philomelos non a caso; ecco il canto originale di cui potete vedere anche il sonogramma, entrambi tratti da xeno-canto).

È incredibile come i canti degli uccelli si possano sentire chiaramente in questo pezzo, come se fossero riprodotti pari pari e nello stesso tempo il brano sia costruito e sviluppato con grande coerenza.
Sentite come i brevissimi frammenti del canto del tordo vengano trattati come dei moduli tematici e sviluppati sia dal punto i vista melodico che ritmico.
Nathan Carterette, pianoforte.
Canti degli uccelli d’Europa (e non)
Updated 20150604

Come ultimo post del 2007, vi segnalo questi siti che contengono canti di uccelli europei e non, registrati sul campo.
I formati sono wav a 8 bit, SR 22050 e MP3.
I siti sono belli è contengono molto materiale, anche se, ad essere sincero, non capisco perché usare un formato come wav a 8 bit, SR 22050. Suppongo per risparmiare spazio, ma il fatto è che un mp3 a SR 44100 e 128 kbps è più piccolo e ha più banda.
Infine, tanto per fare qualche esempio, ecco qualche uccellaccio esotico: il canto della Sariama cristata, e quello, giustamente malinconico, del Passero marittimo (Ammodramus maritimus nigrescens, vedi figura) ormai estinto.
I siti sono:
Suoni e Canti degli uccelli d’Europa contiene anche i sonogrammi e una sezione dedicata agli uccelli rari
Al posto di quello sotto, che ora è dedicato all’osservazione ma non ospita più i canti, vi metto un altro sito molto ricco (segnalato da Simone B.):
Fuglelyder (birdsongs and calls; norvegese, ma con nome scientifico in latino; praticamente gli stessi file, ma in mp3)
Numbers Stations
 Quando ero piccolo (5/6 anni) non c’era la TV in casa, ma c’era una grossa radio. Onde corte, medie, lunghe.
Quando ero piccolo (5/6 anni) non c’era la TV in casa, ma c’era una grossa radio. Onde corte, medie, lunghe.
Una delle mie passioni era proprio ascoltare la radio e soprattutto tutti quegli strani suoni che uscivano dalle onde corte. Ma più di tutto mi appassionavano certe stazioni dalle quali si sentivano voci che parlavano in strane lingue con la cadenza che non era quella di una trasmissione normale, discorsiva, ma piuttosto quella di chi leggeva degli annunci, un po’ nello stile della BBC quando mandava istruzioni ai partigiani francesi con frasi in codice ben scandite, tipo “la gatta ha mangiato tutti i gattini”, oppure come il famoso verso dalla Chanson D’Automne di Paul Verlaine trasmesso in due tranche per annunciare l’invasione: “I lunghi singhiozzi dei violini d’autunno”, prima e poi, a 2 giorni dallo sbarco, l’ultima parte: “mi feriscono il cuore con monotono languore”.
Alcune stazioni, poi, erano piuttosto particolari perché trasmettevano solo serie infinite di numeri, tipicamente in inglese. “One, five, seven, six, eight”; pausa; “nine, eight, two, three, four”; pausa. E così via…
Io conoscevo i numeri in inglese e a volte li trascrivevo cercando di capire se c’era una regola, ma non ne ho mai trovate. Naturalmente immaginavo storie di spie che ricevevano le trasmissioni e poi si lanciavano a decifrare il messaggio.
Quello che allora non sapevo è che era vero. Molto probabilmente era proprio così. Quelle erano le famose numbers stations.
Io lo avrei saputo solo molti anni più tardi, all’università, ma ormai la cosa è nota, al punto da essere riportata anche da wikipedia:
Le numbers station sono stazioni radio in onde corte di origine sconosciuta. Generalmente le trasmissioni contengono una voce che legge sequenze di numeri, parole o lettere (usando talvolta un alfabeto fonetico).
Possono essere individuati tre tipi di numbers station:
- stazioni in fonia, dove i numeri vengono pronunciati da una voce o da un sintetizzatore vocale
- stazioni che trasmettono in codice Morse
- stazioni che trasmettono apparente rumore
Le voci trasmesse sono spesso prodotte da un sintetizzatore vocale e usano un’ampia varietà di lingue, in particolare negli USA spesso sono udite in spagnolo, mentre in Europa le trasmissioni sono generalmente in inglese, tedesco o francese o ancora in lingue slave. Inoltre sono per la maggior parte femminili, più raramente maschili o infantili.
La convinzione popolare, supportata dalle poche prove esistenti sull’argomento, ricondurrebbe queste stazioni operazioni di spionaggio. Questa ipotesi non è stata mai pubblicamente confermata da nessuna agenzia governativa tra quelle che potrebbero gestire una numbers station, tuttavia è accaduto che una stazione, coinvolta in spionaggio, sia stata pubblicamente perseguita da un tribunale di un altro stato.
In realtà le onde corte sono ideali per una comunicazione one way (solo invio, senza risposta) e quindi per mandare ordini o avvisi, perché
- Non hanno bisogno di ripetitori in quanto vengono riflesse dagli strati alti dell’atmosfera e quindi viaggiano seguendo la curvatura terrestre raggiungendo qualsiasi luogo; è solo questione di potenza della trasmissione
- Si ricevono con una radio normale e non sospetta
- Sono complesse da localizzare: bisogna tracciare il segnale in base alla direzione da cui arriva con maggior potenza e poi triangolare
In definiva vanno benissimo per inviare da uno stato, dei messaggi ai propri agenti in uno stato straniero. Il fatto che possano essere intercettate da chiunque non è un problema perché le trasmissioni potrebbero essere criptate con un codice molto forte, come il cifrario di Vernam.
Alcune di queste stazioni hanno anche ricevuto dei nicknames, come “The Lincolnshire Poacher” che trasmette da Cipro, è attribuita all’MI5 e invia le prime due battute dell’omonima canzone folk prima di ogni gruppo di numeri. Oppure la sua “cugina” asiatica che trasmette da Guam con lo stesso formato ed è chiamata “Cherry Ripe” (e naturalmente qui la canzone di stacco è Cherry Ripe). O ancora “Magnetic Fields”, che usa musica di Jean Michel Jarre, o “Atención” che trasmette da Cuba in territorio USA.
Il gruppo ENIGMA, costituitosi proprio per studiare le numbers station, le ha classificate secondo la lingua e le modalità di trasmissione. Nel 1997, l’etichetta Irdial-Discs ha pubblicato un set di 4 CD contenente registrazioni di tali trasmissioni: “The Conet Project: Recordings of Shortwave Numbers Stations”.
Oggi tutto questo materiale è distribuito liberamente dall’Internet Archive.
Ecco alcuni esempi
Localizzatori Acustici

Questi impressionanti oggetti erano localizzatori acustici mobili in forza all’esercito giapponese negli anni ’30 (quello a destra nella foto è l’imperatore Hiroito).
Data la loro somiglianza allo strumento, venivano anche chiamati “tube da guerra”. Definizione impropria in quanto non emettevano alcun suono, ma si limitavano a ricevere e sperabilmente evidenziare a distanza il suono degli aerei in arrivo.
Sotto, invece, vediamo un fantastico paesaggio, con dei localizzatori fissi che danno alla scena un aspetto quasi alieno.
Credo che pochi saprebbero dire senza esitazione a che cosa servono queste costruzioni.
Sono (erano) dei localizzatori acustici, cioè delle strutture progettate prima dell’avvento del radar (fine anni ’30, primi ’40), per intercettare le onde sonore e concentrarle in un punto di ascolto, grazie anche ad un microfono.
Quelli che vedete nelle immagini si trovano in Inghilterra, nel Kent e sono stati costruiti intorno al 1930. Erano in grado di intercettare il suono di un aereo a 20/30 miglia di distanza. Muniti di un microfono, avevano una precisione di circa 1.5 gradi.

Violin Acoustics
![]()
Una eccellente spiegazione della fisica degli strumenti ad arco si può leggere qui.
Ubuntu Linux & realtime Jack
Questo è un post per addetti ai lavori.
Mi sto rendendo conto che, con Ubuntu 7.xx (Feisty Faune), molti hanno difficoltà nel lanciare jackd (un server audio professionale su linux) con l’opzione realtime (-R, necessaria per avere bassa latenza) come utente normale, ma riescono invece a farlo solo come superuser (con sudo), con la rogna di dover lanciare nello stesso modo anche tutti i client.
Alcuni lamentano anche che con la versione precedente si poteva farlo (ed è vero).
La soluzione è molto semplice:
- Controllate che il vostro utente sia inserito nel gruppo audio. Se l’utente è quello creato durante l’installazione, dovrebbe già esserlo. Comunque aprite una console (terminale) e scrivete
idche mostra user id, group id e tutti i gruppi a cui l’utente appartiene. La risposta dovrebbe essere qualcosa come
uid=1000(nome_utente) gid=1000(nome_utente)
groups=4(adm), 20(dialout), 24(cdrom), 25(floppy),
29(audio), 30(dip), 44(video), 46(plugdev), 104(scanner),
112(netdev), 113(lpadmin), 115(powerdev), 117(admin),
1000(nome_utente)
[al posto di 1000 potreste vedere un altro numero]Se c’è già il gruppo 29(audio), allora tutto ok, altrimenti aggiungete l’utente al gruppo audio.
- Editate il file /etc/security/limits.conf come superuser con il comando
sudo gedit /etc/security/limits.conf
[al posto di gedit potete mettere il vostro text editor preferito] - Alla fine del file, prima della riga
# End of file
aggiungete quanto segue:@audio - rtprio 99
@audio - nice -10
@audio - memlock 256000
[il valore 256000 è adatto a una RAM di 512K; è la memoria da bloccare e dovrebbe essere circa la metà della vostra RAM; mettete 512000 se avete 1 Gb e così via]
[il valore nella seconda linea (nice) è proprio -10 (meno 10); imposta la priorità e senza il meno avrete una proprità schifosa] - A questo punto è necessario riavviare il computer.
Ora potete anche lanciare jackd in realtime come utente con il comando
/usr/bin/jackd -R -dalsa -dhw:0 -r44100 -p1024 -n2
[ovviamente potete aggiungere anche altre opzioni]oppure con un front-end grafico come qjackctl o simili. - Naturalmente è meglio installare anche il kernel low-latency.
MIDI Controllers
Controller Zone è una interessante pagina che raccoglie link ai produttori di una serie di superfici di controllo MIDI, cioè quegli oggetti che permettono di inviare dati MIDI tramite faders, potenziometri e bottoni, oppure con sistemi un po’ meno usuali come un theremin MIDI o un sistema che genera dati a partire dalle onde cerebrali.
Sonic Visualizer
![]()
Un ottimo software per l’analisi del suono e per di più open source e gratuito sviluppato presso il Centre for Digital Music at Queen Mary, University of London.
Prodotto per Linux e Windoze (io ho provato solo il primo, ma suppongo siano uguali), dispone, fra l’altro, di FFT, spettrogramma 2D, stima del pitch e possibilità di inserire annotazioni in overlay. Su Linux è in grado di utilizzare tutti i LADSPA plugins per l’elaborazione audio. Ottimo per il ricercatore e per il musicista elettronico. Cliccate sull’immagine per ingrandirla.
Ecco il sito da cui scaricarlo e la pagina delle features.
Cilindri e dischi


1877: Edison registra la voce umana (“Mary had a little lamb”) mediante solchi incisi su un cilindro di stagno.
Per avere un’idea della resa, questa è la voce di Edison registrata da uno dei suoi fonografi. Non è male pensando all’epoca, ma ovviamente è voce parlata, quindi a banda limitata; la musica sarebbe venuta molto peggio. È interessante notare come Edison si rendesse perfettamente conto dei suoi limiti: il fonografo, infatti, non venne pubblicizzato come apparecchio per incidere musica, ma come dittafono per ufficio o per l’archiviazione di discorsi e di testimonianze di vari tipi (processi, riunioni, etc). La storia lo smentirà in breve.
Il fonografo fu brevettato nel 1878.
Negli anni seguenti altri inventori cercarono di migliorare il prototipo di Edison apportando varianti tali da giustificare altri brevetti (non si brevetta l’idea, ma l’oggetto). Nel 1885, Bell e Tainter brevettarono il “grafofono” che usava cilindri ricoperti di cera, mentre, nel 1887, Berliner creò il “grammofono” che incideva un disco al posto del cilindro.
Quest’ultimo fu il primo ad arrivare alla produzione di massa nel 1888 con un disco di 7 pollici che girava a 30 giri/min. (2 min di durata). Ma, solo un anno dopo, Edward D. Easton fondò la Columbia Phonograph Co. con l’idea di commercializzare un sistema a cilindri. Era l’inizio della lotta “cilindro contro disco” che continuerà fino al 1913.
Sopra: il Fonografo di Edison e i solchi di “Mary had a little lamb”.
 Nel 1890 abbiamo il primo jukebox a cilindri. Esposto al San Francisco’s Palais Royal Saloon e funzionante a monete, incassò più di $ 1000 in 6 mesi nonostante disponesse di soli 4 cilindri.
Nel 1890 abbiamo il primo jukebox a cilindri. Esposto al San Francisco’s Palais Royal Saloon e funzionante a monete, incassò più di $ 1000 in 6 mesi nonostante disponesse di soli 4 cilindri.
La produzione di massa inizia nel 1893: Berliner vende 1000 grammofoni e 25000 dischi. In pochi anni vengono fondate varie etichette discografiche, fra cui Victor e Odeon.
Nel 1903, in Europa, si vendono dischi da 10 pollici (circa 25 cm, durata 4 minuti) di artisti famosi come Caruso. Viene registrato l’Ernani, di Verdi, su 40 dischi. Si realizza un prototipo di disco inciso su ambo i lati. A lato: il famoso logo della Victor.
1908: i primi famosi cantanti americani dell’epoca (John Lomax, John McCormack) firmano contratti discografici.
Nel 1910 erano già disponibili dischi a 78 giri con formati da 7 a 21 pollici e durata fino a 8 minuti. Nel frattempo (1909) era stata inventata la bakelite, una resina plastica con cui i dischi venivano costruiti e stampati a caldo.
Anche per i musicisti si apre l’era della riproducibilità tecnica che, insieme alla radio inventata nel 1894, rivolta letteralmente il modo in cui si concepisce la musica.
The FreeSound Project
Il Freesound Project è gestito dall’Universitat Pompeu Fabra di Barcelona. Il fine del progetto è la creazione di un database di campioni audio distribuiti sotto licenza Creative Commons Sampling Plus e quindi liberamente riutilizzabili.
Oltre alle solite modalità di consultazione, basata su tags, è anche possibile ricercare sonorità simili o dissimili. Molti campioni di tipo ambientale hanno anche un tag geografico (geotag) che indica la località di registrazione, selezionabile da una mappa.
Naturalmente, tutti possono contribuire. Il db ormai contiene più di 500.000 suoni
Venti di Titano
Questa non è una composizione musicale e forse è noiosa, ma ascoltatela.
È il suono registrato dal microfono posto a bordo della sonda Huygens, parte del progetto Cassini di esplorazione dei pianeti esterni, durante la sua discesa di un anno fa su Titano, satellite di Saturno e unica luna del sistema solare con un’atmosfera.
Per quelli che sanno sognare…
Do not go gentle into that good night
 L’esperienza che vi propongo qui è sempre audio, ma è un po’ diversa dal solito.
L’esperienza che vi propongo qui è sempre audio, ma è un po’ diversa dal solito.
Noi non abbiamo la consuetudine della lettura di poesia. Gli anglosassoni, invece, ce l’hanno ed è una gran cosa, soprattutto quando a leggere sono gli stessi autori.
Recentemente, Salon.com ha messo in linea tutta la Caedmon Collection, una serie di registrazioni eseguite fra il 1952 e il ’53, in cui Dylan Thomas legge una vasta selezione della propria poesia e prosa, insiema a qualche brano dei suoi autori preferiti, fra cui Shakespeare, Milton, Eliot, Auden, Hardy, Lawrence, Graves e il suo amico Vernon Watkins.
Da questa raccolta, ecco la famosissima “Do not go gentle into that good night”, dedicata al padre morente, letta da lui stesso.
L’impostazione vocale di Dylan Thomas è chiara e diretta, di grande potenza, ma con molte sfumature espressive. D’altronde, i suoi reading erano affollatissimi e la gente rimaneva fuori dai teatri o dai cinema in cui il poeta si esibiva, per mancanza di posto.
| Do not go gentle into that good night, Old age should burn and rave at close of day; Rage, rage against the dying of the light.Though wise men at their end know dark is right, Because their words had forked no lightning they Do not go gentle into that good night.Good men, the last wave by, crying how bright Their frail deeds might have danced in a green bay, Rage, rage against the dying of the light.Wild men who caught and sang the sun in flight, And learn, too late, they grieved it on its way, Do not go gentle into that good night.Grave men, near death, who see with blinding sight Blind eyes could blaze like meteors and be gay, Rage, rage against the dying of the light. And you, my father, there on the sad height, |
Non andartene docile in quella buona notte, vecchiaia dovrebbe ardere e infierire quando cade il giorno; infuria, infuria contro il morire della luce.Benchè i saggi infine conoscano che il buio è giusto, poichè dalle parole loro non diramò alcun conforto, non se ne vanno docili in quella buona notte.I buoni che in preda all’ultima onda splendide proclamarono le loro fioche imprese, avrebbero potuto danzare in una verde baia, e infuriano, infuriano contro il morire della luce.I selvaggi, che il sole a volo presero e cantarono, tardi apprendono come lo afflissero nella sua via, non se ne vanno docili in quella buona notte.Gli austeri, vicini a morte, con cieca vista scorgono che i ciechi occhi quali meteore potrebbero brillare ed esser gai; e infuriano infuriano contro il morire della luce. E tu, padre mio, là sulla triste altura io prego, |
L’Universo non è user friendly anche se lo sembra

Signore e signori, vi presento il Kakophone.
Questo divertente sintetizzatore virtuale genera una quantità infinita di suonerie personalizzate in diversi stili. Poi ve le manda al vostro indirizzo email. Tutto gratis. In cambio vi chiede solo di iscrivervi a una newsletter, verosimilmente pubblicitaria, che poi potete annullare.
L’oggetto è effettivamente molto simpatico. Fa un sacco di rumorini graziosi. Immagino che torme di ragazzini si siano immediatamente fiondati sul sito. Provatelo anche voi. Però, prima, seguite questo ragionamento.
Dunque, per prima cosa il kakophone vi chiede il vostro numero telefonico che appare sotto forma di bar-code nell’immagine (sulla destra sotto alla freccia; 789… non è il mio). Il numero serve come base per un generatore di numeri casuali ed è quello che assicura che una suoneria non possa essere duplicata. Dal punto di vista informatico è corretto. Ovviamente potete dare un numero qualsiasi, ma di solito non ci si pensa. Anch’io ho dato il mio.
Poi voi giocherellate con l’oggetto. Generate un po’ di suonerie e ne scegliete una. A questo punto il programma te la deve inviare come file perché tu possa caricarla nel telefono e ti chiede nazionalità, marca e modello del telefono e email.
E qui mi sono bloccato. Perché, così facendo, il sito conosce e associa
- la mia nazionalità
- il mio numero di telefono
- la mia email
- marca e modello del mio telefono
Non male. Vi rendete conto? Va bene che non può esserne sicuro e io sono tendenzialmente paranoico, ma le vie di internet sono infinite…
Pianoteq
Sempre la Piano Society (vedi post seguente) distribuisce anche Pianoteq, un software di simulazione del pianoforte basato su modelli fisici, particolarmente potente, versatile. Costa € 249, in linea con “Steinberg The Grand”, ma può essere scaricato e provato per 45 giorni. Questa è una pagina piena di demo.
Vi consiglio di provarlo. I modelli fisici danno ottimi risultati, senza quei salti di sonorità tipici del campionamento. Ecco le caratteristiche tecniche tratte da questa pagina.
- The piano sound is constructed in real time, responding to how the pianist strikes the keys and interacts with the pedals.
- It includes the entire complexity of a real piano (hammers, strings, duplex scale, pedals, cabinet).
- No quantization noise (32-bit internal sampling at 192 KHz).
- Real progressive variation of the timbre (127 velocities per note).
- Adjustable hammer hardness (voicing) and other similar parameters.
- Adjustable unison width (tuning) and other similar parameters.
- Adjustable piano size (soundboard) and other similar parameters.
- Adjustable spectrum profile, based on the first 8 overtones.
- Progressive sustain pedal, allowing partial-pedal effects.
- Sostenuto pedal, harmonic pedal and Una Corda (soft) pedal.
- Very fast to install and initialize.
- Total size is just 8 MB (MegaBytes).
- It can be used successfully with a laptop (low hardware requirements).
- Adjustable optional samples of acoustic noises (pedal and key release).
- Built-in graphic equalizer with freely adjustable key points.
- Built-in graphic velocity curve with keyboard presets.
- Built-in reverb unit with presets.
Fra i demo, vi faccio ascoltare questi (ma, valutandoli, pensate anche a che casse avete):
- Nocturne No. 3 Liebestraum (F. Liszt)
- La Fille aux Cheveux de Lin (C. Debussy)
- Improvvisazione demo
Cronologia della Musica Elettroacustica

Un po’ di autopromozione non guasta.
Vi segnalo la mia Cronologia della Musica Elettroacustica, una pagina piena di stravaganti curiosità come la voce di Edison registrata da uno dei suoi fonografi alla fine dell’800, oppure un incredibile carillon orchestrale con ance, flauti, campane, piatti, tamburi costruito in Svizzera da Gueissaz nel 1904 e inviato a San Pietroburgo per essere donato dallo Zar allo Scià di Persia, e naturalmente il suono dei primi strumenti elettrici e altro ancora.
Evidentemente abbiamo un problema di deciBel
Gli esempi contenuti in questa pagina mostrano chiaramente l’aumento della compressione e del volume portato fin oltre il limite del clipping, di cui abbiamo parlato qui.
Il titolo è chiaro: “The Death Of Dynamic Range”.
A quanto sembra, ormai la musica pop viene mixata e compressa nello stesso modo della pubblicità: range dinamico quasi nullo e alto volume fisso stabile nel tentativo di bucare la radio.
Lo stesso articolo rileva anche un’altra cosa interessante: a volte lo stesso pezzo viene compresso in modo diverso per il mercato occidentale rispetto a quello asiatico, il che suggerisce che si prenda in considerazione qualche parametro a me sconosciuto (il livello medio delle radio? le abitudini del pubblico?) nella realizzazione del master. Ma, pensandoci, potrebbe anche essere un caso: un tecnico di masterizzazione diverso che interpreta secondo il suo giudizio le istruzioni della dirigenza.
Un problema di deciBel?
Recentemente è apparsa una lettera aperta di un executive dell’industria musicale che ha sollevato un caso. Questo signore, tale Angelo Montrone, è il vice presidente del dipartimento A&R (Artists & Repertoire) della One Haven Music, che fa parte della Sony.
In breve, lui lamenta l’eccesso di compressione e di riempimento, con conseguente incremento di volume, nelle incisioni attuali, rispetto, per es., a quelle degli anni ’80. Il tutto condurrebbe a un eccessivo affaticamento dell’orecchio, che comporterebbe una prematura sensazione di stanchezza degli ascoltatori.
Cito un estratto:
There’s something . . . sinister in audio that is causing our listeners fatigue and even pain while trying to enjoy their favorite music. It has been propagated by A&R departments for the last eight years: The complete abuse of compression in mastering (forced on the mastering engineers against their will and better judgment).
Fra le altre prove, porta due incisioni dello stesso gruppo, Los Lonely Boys, a vari anni di distanza. Ascoltate i Lonely Boys vari anni fa e oggi. Notate che effettivamente le canzoni sono simili, ma l’arrangiamento attuale è molto più pieno e il livello medio è più alto.
La cosa mi ha incuriosito perché anch’io a volte ho questa sensazione.
Ci sono due modi di misurare l’ampiezza di un suono (quello che viene generalmente chiamato volume): l’ampiezza di picco e l’ampiezza RMS.
Il primo misura l’ampiezza istantanea dei picchi, cioè i punti con il volume più alto che però hanno durata minima. Fisiologicamente il dato è importante perché sono proprio i picchi improvvisi molto alti che possono provocare danni al timpano (il meccanismo difensivo del timpano, infatti, impiega circa 1/10 di secondo per entrare in azione).
Il secondo, invece, è una media che ha senso su lunghe durate (anche 1 minuto o più). Dal punto di vista fisiologico, un alto livello di ampiezza RMS affatica il sistema uditivo. Chiaramente è quest’ultimo che viene tirato in ballo da Mr. Montrone.
Trattandosi di CD, cioè di cose che non hanno un volume assoluto perché dipendono dall’amplificazione, tutte le misurazioni si fanno rispetto rispetto al massimo teorico del CD, che è uguale per tutti i dischi ed è la massima ampiezza possibile usando 16 bit, lo standard del CD audio.
Di conseguenza, si misura la distanza dal massimo possibile, definito come 0 dB. Si guarda, cioè, quanto l’incisione ha saturato l’ampiezza disponibile e per quanto tempo.
A questo punto, sono partite le misurazioni. Si è scoperto che, nella seconda metà degli ’80, l’ampiezza media (RMS) dei dischi di pop music era intorno ai -15 dB, cioè 15 deciBel sotto il massimo possibile. Attualmente, invece, la media si è alzata a valori he vanno da -12 a -9 dB, cioè l’incisione è molto più saturata (pensate che una differenza di 6 dB equivale al doppio).
Le mie misurazioni confermano questa tendenza. Bisogna considerare che io non ho molti dischi recenti e che in ogni caso i miei gusti sono un po’ particolari. Le cose più normali che ho sono i King Crimson o Peter Gabriel, mentre servirebbero dischi da top 10.
Comunque, posso aggiungere che, se effettivamente i dischi dei tardi anni ’80 sono incisi a circa -15 dB di media, nei primi ’80 eravamo a circa -19 e negli anni ’70 (rimasterizzati) a -22 dB.
La corsa al rialzo, quindi, non è solo recente, ma esiste da sempre.
Cos’è, è semplice dirlo. Si tratta del modo di comprimere. In pratica l’incisione viene prima compressa, riducendo le differenze fra i piano e i forte, poi la media viene alzata per occupare la parte superiore del range di ampiezza. Adesso, con la registrazione a 24/32 bit, si può fare ancora meglio.
In tal modo, il brano suona più forte, più grintoso, ma anche più piatto, con meno differenze dinamiche.
È più difficile, invece, capire perché sia nata questa mania. Non dipende solo da un mutamento di genere. Stiamo parlando delle top 10, non del punk.
Sembra dipendere, più che altro, dal modo di fruire la musica. Oggi si ascolta in un modo diverso da 20/30 anni fa. In macchina, in treno, mentre si corre, dal computer, etc. E così la musica deve competere con altri suoni. Forse.
74 minuti
Mi sento da schifo. Mal di gola, forse febbre. L’arrivo del caldo mi ha fregato. Immaginando che non ve ne freghi più di tanto, vi passo una curiosità sul CD e vado a dormire.
Dunque, la durata del CD Audio è fissata dagli standard in 74 minuti. Questo non significa che tutti i CD debbano durare tanto, ma che un supporto, per aderire allo standard CD Audio, deve avere determinate caratteristiche che, fra l’altro, fanno sì che possa ospitare almeno 74 minuti di audio stereo, 16 bit, SR 44100 (i CD da 80 sono arrivati dopo e 74 min. è sempre rimasta la durata minima; notare che il prototipo Philips era un disco da cm 11.5 invece di 12 e di durata 66 min.).
Ma perché proprio 74 minuti? Forse perché era il massimo possibile o ragionevole all’epoca? No. Sarebbe stato facile arrivare anche a 75 o 76. D’altra parte, se il problema era di non stringere troppo le tracce, 72 o 70 minuti sarebbero stati più ragionevoli. Perché proprio 74?
La leggenda, riportata da molte fonti come vera, racconta che Philips/Sony scelsero 74 semplicemente per farci stare l’intera 9a Sinfonia di Beethoven che, nelle esecuzioni dell’epoca, aveva una durata che si avvicinava a questo limite.
In realtà alcune esecuzioni duravano anche di più. Per esempio, la versione di Kubelik del ’74 arriva a 77’16”. Quindi il problema si sposta a quale versione si voleva mettere in un solo CD.
Qui le leggende divergono. Una prima versione afferma che si trattava di una versione di Karajan di circa 73′ incisa per Polygram che allora era parte di Philips. Questo spiegherebbe la volontà di Philips di pubblicare l’esecuzione di uno dei propri artisti più famosi in un solo CD. La cosa è stata confermata dallo stesso Karajan in una intervista. Ma la stranezza è che l’esecuzione in mio possesso, su CD DG del ’77 dura solo 67′. Esiste una versione di Karajan che supera i 70′?
La seconda versione ne dà una spiegazione più banale/romantica, in base ai punti di vista. Secondo quest’ultima, la versione della 9a era quella preferita dalla moglie di Norio Ohga, altissimo dirigente Sony e presidente dal 1982. Anche in questo caso, la leggenda è avallata da un’intervista del 1992 allo stesso Ohga.
Comunque sia, è certo che la 9a di Beethoven è stata presa in considerazione nella definizione dello standard CD Audio perché vari documenti Philips dell’epoca la consigliano come opera di test della qualità di un supporto, sia per l’escursione dinamica che per la durata “vicina al massimo teorico”.
Convolution for fun & profit
Un po’ di auto-pubblicità non guasta.
A tutti gli amanti e i lavoratori dell’audio digitale consiglio di andare a leggersi il mio ultimo articolo sulla creazione di riverberi mediante convoluzione, sistema che, a mio avviso, dà risultati nettamente superiori ai tradizionali riverberatori a più stadi.
Ascoltate gli esempi e fatemi sapere.
SoundTransit
SoundTransit è un interessante sito che propone viaggi (ad occhi chiusi) attraverso concatenazione di file audio. Il sito si inserisce nel filone soundscape e raccoglie registrazioni di suoni ambientali sia esterni che interni inviate dagli utenti di tutto il mondo.
A questo punto si può sia frugare fra i file audio, tutti corredati di note, luogo e dati di registrazione (più di 700 alla data di questo post), che definire un percorso che collega due luoghi mediante il montaggio in dissolvenza di file sonori.
Un’idea carina che mostra come trarre qualcosa di originale da un semplice archivio.
Campionamenti strumentali
L’Università dell’Iowa mette a disposizione campionamenti strumentali di buona qualità liberamente scaricabili. Per ogni strumento trovate vari file in formato aiff, ognuno contenente una scala di una 8va oppure singole note, tali da coprire l’intera estensione. Tutti i file, inoltre, sono disponibili 3 dinamiche (pp, mf, ff).
Trovate il tutto in questa pagina.
Sound Seeker
Avete presente le webcam? Quelle simpatiche videocamere che ci permettono di vedere in tempo reale qualche luogo lontano combinando il fascino tecnologico del delirio da onnipresenza con il piacere del voyerismo?
Bene. Adesso, per iniziativa del World Forum for Acoustic Ecology (WFAE) e della sua sezione di New York (NYSAE), abbiamo anche un equivalente acustico. Il progetto Sound Seeker, per ora limitato alla città di New York, consiste in una serie di microfoni piazzati in vari punti della città che l’utente può selezionare ricevendo uno stream audio in presa diretta.
Il sistema è stato sviluppato in collaborazione con Google Maps le cui immagini vengono utilizzate come sfondo su cui sono posizionate le icone dei microfoni da selezionare.
Il WFAE esiste in forma di associazione non-profit dal 1993 e si occupa del monitoraggio dei paesaggi sonori del pianeta e dello studio dell’influenza umana su di essi. L’associazione nasce dallo sviluppo dell’ormai famoso WorldSoundscape Project che per primo si è sforzato di studiare a fondo gli ambienti acustici ed elevare il livello di attenzione sul loro stato.